2023
Navigation
Jan - Feb - Mar - Apr
May - Jun - Jul - Aug
Sep - Oct - Nov - Dec
Resources
C++ Initialization 1/5/2023
What is a Semiconductor? 1/14/2023
Static Variables in C 1/15/2023
Memory Layout of C Programs 1/15/2023
What is constinit in C++ 1/18/2023
Understanding constexpr in C++ 1/18/2023
Lecture on constexpr 1/19/2023
C++ Graph Implementation 1/21/2023
More on Graphs 1/22/2023
What is a Git SSH Key? 1/22/2023
GitHub SSH Key Fingerprints 1/22/2023
Character Strings in C 1/25/2023
adafruit PIR Motion Sensor 1/25/2023
Learn DSA 1/27/2023
Time Complexity Examples 1/27/2023
Circular Linked List Split 1/29/2023
Sort a Matrix Problem 1/31/2023
The Evolution of CPU Processing Power 2/6/2023
Programming a Raspberry Pi Pico with C or C++ 2/6/2023
Tips for Embedded Study 2/10/2023
Compute the Integer Absolute Value Without Branching 2/14/2023
Bit Twiddling Hacks 2/14/2023
madewithwebassembly.com 2/19/2023
UART Protocol Explanation 3/1/2023
Magnetic Core Memory 3/6/2023
How Transistors Work 3/6/2023
7 Best Artificial Intelligence (AI) Courses for 2023 4/10/2023
Minimax With Alpha Beta Pruning 4/16/2023
Alpha Beta Pruning / Cuts 4/16/2023
Project CETI 4/25/2023
ChatGPT Release Article 5/2/2023
Tree of Thoughts Academic Paper 5/20/2023
Multi-Dimensional Data (as used in Tensors) - Computerphile 6/4/2023
Tensors for Neural Networks, Clearly Explained!!! 6/4/2023
How to implement KNN from scratch with Python 7/8/2023
IBM: What Is Gradient Descent? 7/19/2023
An Introduction to Linear Regression Analysis 7/19/2023
How to Calculate Linear Regression Using Least Square method 7/19/2023
Gradient Descent Algorithm — A Deep Dive 7/19/2023
Google Colab - 10 Tips 8/27/2023
Importing Kaggle Datasets into Colab 8/30/2023
Documentation For scipy.signal.spectrogram 9/7/2023
Heap Sort Explanation - GeeksForGeeks 10/10/2023
C++ Friend Functions - tutorialspoint.com 10/10/2023
Image Annotation - makesense.ai 10/23/2023
Hugging Face Dataset Walkthrough 10/23/2023
Instance Segmentation vs Object Detection 10/23/2023
Ultralytics Documentation 10/29/2023
Fix Image Rotation on iOS 11/2/2023
My Programs
adjacency_list1.cpp 1/22/2023
adjacency_matrix1.cpp 1/22/2023
circular linked list 1/28/2023
Sort A Matrix 2/1/2023
Stack 2/2/2023
func_ptr.c 2/9/2023
mergeSort1000 2/11/2023
sfmlPractice0 2/20/2023
sfmlPractice1 2/22/2023
1/1/2023
Code - Book
Read more of chapter 17, “Automation”. I’m learning about how an array of “instructions” such as Load, Add, Store, and Halt can be applied to a data array in order to perform arithmetical operations. I can see where this is going: the book is barely scratching the surface of assembly code and showing how it interacts with data.
Linux Pocket Guide
Learned how to examine the permissions of a given file or directory: ls -l myfile the resulting line will look something like this -rwxrwxrwx username username timestamp the 10-char string at the beginning tells what type of list element it is with the first char and then the remaining nine chars show what permissions three different groups have. In the example above, all groups can read, write, and execute.
1/2/2023
Mastering Data Structures and Algorithms
I can see that this course would be very instructive, and I foresee that I will use it in the future, but I think it might be the wrong choice for the nonce. I realized I’d like to explore C++ more deeply before taking a course solely dedicated to data structures and algos.
C++20 Masterclass - Udemy
I’m excited about this course. I hope I can complete it in about 3.5 months, but we’ll see! I watched sections 1 through 4. The instructor advised us to watch the environment setup videos for every OS, even if we weren’t using a particular one. This way, we could learn how it is done on each. Ultimately, I got VSCode set up on my Linux machine. We used the terminal to check whether GCC and Clang were installed, then we installed them if they weren’t already installed, then we edited the tasks.json file in our project folder to allow us to easily build with either compiler, and finally we told VSCode to use the C++20 standard in a file called c_cpp_properties.json, which was created after accessing the command palette and entering C/C++:Edit Configurations (UI).
1/3/2023
Code - Book
Currently reading the section of Chapter 17 on making the adding machine more flexible. Now, we include 2 bytes with every instruction opcode to tell the CPU where to perform the instruction. This is more flexible than using two contiguous arrays (instruction array and data array) that must be always synchronized, instruction memory address to data memory address. I find all this very fascinating and I'm eager to make it all more intuitive as I continue studying!
C++20 Masterclass
Finished watching sections five and six. I'm glad I did because they helped solidify the VSCode setup process. I like the idea of having a template project folder that I can simply cp template_project and mv template_project project_name. I am eager to get fully underway with this course, but I'm trying to make sure I don't overwork myself. Slow and steady wins the race, and I'm racing myself.
Bare Metal C
I went through the earlier part of Chapter 3 and refreshed myself; key terms are HAL (Hardware Abstraction Layer) and GPIO (General Purpose Input Output). Since I had already written the demo program last time, I simply reviewed it to make sure I understood every part of it. I’m pleased that this book goes so in depth on the build process, compiling and linking. It’s possible that I will breeze through some parts of this book since it is geared toward beginner C programmers, but I know there will be many new concepts scattered throughout.
1/4/2023
C++20 Masterclass
I worked through all the videos in Section 8. Much of it was review for me, but I still sensed the value in it. Also, it helped to increase playback speed where I already completely understood what was being taught. My biggest takeway was the difference between Core Features, Standard Library and STL (Standard Template Library). The instructor did not go in depth, but I know these categorical distinctions will be useful later on. The demonstration of the getline() function was also useful. This is how we used it:
std::string name;
getline(std::cin, name);
1/5/2022
C++20 Masterclass
Watched and worked through section 9 videos 39 and 40. Nearly all of this material is review, but once again, I just increase playback speed and skim through them. Occasionally, some simple new concepts have emerged, which is the main reason I don't want to skip anything.
Yes! Video 41 presented some new material and it all checks out with stackoverflow. The main takeaway from this video was three types of initialization: braced, functional, and assignment. Braced initialization is the preferred method since it does not allow the data to be altered or truncated if the variable is mishandled. This post on stackoverflow.com explains the concept further - they call it list initialization.
I also watched video 42 and it was also helpful. This is going to be a great course.
1/8/2022
Thoughts
I'm chipping away at this C++ course and really enjoying it! However, I've been feeling discouraged since I'm not working on any projects and I've been unsure of what I should be working on. Today I decided to do some research and find out what interests me. First, I looked at Socket Programming, but I think I found that it is merely a component of the larger topic of web programming, a field that I've thought about exploring more. The trouble is that web programming doesn't seem to excite me very much (of course that could change as my experience grows).
After more browsing, I found the topic that sparked immediate interest IoT (Internet of Things). It includes all the things I think I like: embedded systems, working with C/C++, low-level programming, understanding how data is transmitted over networks via protocols, etc. I might look back at this and chuckle at my obvious inexperience. Anyhow, I need to find what I'm interested in and lean that direction. I need to not set up artificial barriers for myself!
C++20 Masterclass
I completed the video 43, fractional numbers. Then, I wrote a practice program, implementing a pythagorean theorem function using some of the principles (braced initialization, setprecision, default arguments) I've learned.
Video 44, on boolean values, gave me the idea to store multiple boolean values in 1 byte. I wrote a program to do just that.
I finished the rest of Section 8. I found the auto keyword the most significant: it allows us to use C++ in a more-or-less dynamically-typed fashion. I have yet to see where this keyword is most useful, but I'm sure I will in the coming lectures.
Bare Metal C
I finished chapter 4. The main takeaways were from exploring the files created by the IDE at the creation of the project and from using GDB, the debugger. This chapter helped me appreciate just how much goes on under the hood, all the preliminary steps and initializations that must occur just so I can write my tiny LED-blinking program. HAL_init() caught my attention the most since it has a catalog of hardware architectures from which it initializes the hardware with the appropriate data. If you can’t tell, I don’t fully understand it yet!
1/9/2023
Research
I'm exploring potential specializations in technology, and IoT and TinyML currently stand out the most. At the moment, I can't decide between the two!
I went on LinkedIn to add my certificate from the C Programming Udemy class, create a profile summary that explains what my current job is and how I'm preparing for the future by studying Computer Science, and update my CS50x certification with the verified certificate, which I received a few days ago!
C++20 Masterclass
Completed lectures 49 through 51. This stuff was pretty basic! At the end of the lecture on Precedence and Associativity, the instructor explained that a programmer should not rely on the precedence table too much. That is to say, put parentheses in your expressions to make your intentions explicit. This will increase readability and decrease the potential of mishandling data.
Bare Metal C
Began working in chapter 4. The first part of the chapter is mainly about data types, so it is just review. Later in the chapter, I see that we’ll be getting to some content that should fill in some knowledge gaps for me.
1/10/2023
C++20 Masterclass
Sections 52 - 55. Topics covered: Increment Operators, postfix and prefix; Compound Assignment Operators (+=, -=, *=, /=, %=); Relational Operators (<, >, <=, >=, ==, !=); Logical Operators (&&, ||, !). Once again, this is pretty much all review. I’m glad to go over it, but I’d really like to get into the new stuff more.
1/11/2023
C++20 Masterclass
Sections 56 - . Video 56 was quite long, but very useful. It covered output formatting with demonstrations of several functions and manipulators that can be applied to std::cout to alter how the data is displayed in the console.
57 was on the numeric_limits class, which is found in the std::numeric_limits\<unsigned int\>::min() and std::numeric_limits<unsigned int>::max(), we are able to see that the unsigned int data type indeed goes from 0 to over 4 billion.
The weird integral types lecture explained that the int data type is the smallest type with which we can perform arithmetical operations. This is due to the design of the processor. If we take two chars or two shorts and add them, the result will be automatically cast as an int; in order to do this, the compiler has to convert each variable to int beforehand.
With that, I've completed section 9! That's all for today with this course.
Bare Metal C
I read a little more of chapter 4, and it was mostly review again. This is becoming a bit of a trend with my classes. Perhaps I need to be less of a completionist and know when to skim. I’m fine with being a completionist with the C++20 Masterclass, but with this book, I ought to start skimming ahead to content that is new.
The section Standard Integers in chapter 4 was actually very enlightening. The C standard only defines the integral types relative to each other (short is smaller than int is smaller than long). However, on some system, int is 2 bytes, and on others, it's 4 bytes (more common). To deal with this unpredictability, fixed-width data types were added with the stdint.h library (int32_t). These guarantee a specific width (conditional compilation). However, we can still run into something called argument promotion, which is where a data type like int8_t is promoted to int32_t to accomodate a value which cannot be stored in the smaller width. In embedded programming, we don't want data types being manipulated under the hood. We want total control of their width, so that our program runs exactly as intended. Thus, it's better that the value overflow than get promoted.
1/12/2023
Bare Metal C
I definitely spoke too soon with yesterdays first entry for this book. I'm learning some awesome things now. Chapter 4, starting from Shorthand Operators, started to challenge me: it seems to explain that increment and decrement operators should only be used on their own lines of code, not like this while (arr[++i]);. This seems to be perfectly legal C; I'll have to investigate further. Then, we got into Memory-Mapped I/O Registers Using Bit Operations. Here the book introduced us to bitwise operators. I copied down the program on pages 73-74, and It found it probably the most elucidating part of the chapter. Finally, I answered all the questions at the end of the chapter. For question 2b, I found that I needed to clear any values that might be present in the parity bits before reassigning them to a different value:
// clear Parity
ledRegister &= ~Parity; // Parity is 0b00001100
// set Parity to 2
ledRegister |= 0b00001000;
1/13/2023
C++20 Masterclass
Lecture 62 on Literals. I thought I knew exactly what literals were beforehand, but this lecture gave a more nuanced understanding: at the moment, I would describe a literal as any value that is stored in the program binaries after compilation. In other words, if I have a program that takes input from the user,
int not_a_literal;
std::cout << "Enter an integer: ";
std::cin >> not_a_literal;
std::cout << "You entered " << not_a_literal << std::endl;
then I could use a non-literal (not_a_literal). This, int literal;, must be a literal. QUESTION: if a variable is uninitialized, does that make it a non-literal? I think the answer is yes.
[EDIT from 1/28/2023] My understanding here is incorrect. A literal is in fact simply the value used to initialize a variable.
1/14/2023
Bare Metal C
Today was a light day, but I did manage to get a little study in. I read quickly through the first 6 pages of chapter 5 since it was entirely review. It was all about loop and conditional statements. I stopped just before the section entitled "Using the Button"; I'm fairly certain this section will provide me with new material to digest.
Miscellaneous
I realized I don't have a full understanding of the semiconductor, which is a key component of the modern computer (if not THE key component). I pulled up a tab, What is a Semiconductor, and did a cursory read through. I fully intend to revisit this topic soon.
1/15/2023
Bare Metal C
Completed chapter five today, though I've yet to solve all the problems at the end. Here are the main takeaways from Chapter Five starting from the section entitled "Using the Button":
- We were shown three types of input circuitry: pullup, pulldown, and floating. These all have to do with how current is directed before closing the circuit and how it is redirected after closing it.
- When analyzing the code in "The Break Statement" section, I noticed the static keyword and I wanted to refresh myself on its purpose. I found an article on GeeksForGeeks that explains static allocation very well. From there I found another article on the memory layout of C programs. I found the following image very helpful:

BSS, the block of memory where static variables are stored, stands for "Block Starting Symbol". The static keyword causes a variable to be stored in the .bss segment of memory; furthermore, it can be used to make a variable global even if it is declared within some local scope.
1/16/2023
Bare Metal C
It took me far too long to solve chapter 5 problem 1; it's because I was trying to minimize the number of variables and use only two for loops, printing the product of their iterator variables. I completed the program, but I needed to use one initial for loop to set the column headers (X 0 1 2 3 ...).
I solved problem 2 much quicker and had a lot more fun! I enjoy anything that involves bitwise operations; it feels sneaky. For this problem, I had to write a program that could count the number of bits set to 1 in a 32-bit unsigned integer. I did it by running a for loop 32 times while ANDing the number against a 32-bit test value (0x80000000), only the most significant bit set to 1. If the result of the AND is equal to the test value itself, then a count variable is incremented. This is how I counted the number of bits.
I solved problem 3 this evening. I'm proud of my solution: I was able to make my program more user-friendly by using familiar musical jargon. All the user has to do is specify the TimeSignature and Tempo and then populate the uint8_t array with the beats on which they want the light to flash.
1/17/2023
Bare Metal C
Solved problem 4, which asked me to write a program that blinks out "HELLO WORLD" in Morse Code on the Nucleo board LED. Once again, I took it a step further and gave the user the ability to easily change the message as they like. I did this by implementing a Morse Code alphabet matrix and a simple hash function. The user simply types their message into a string literal using only uppercase alpha chars and spaces. The program then interprets this at Morse Code.
Problem 5 tasked me with writing a program that computes the first 10 primes. I wrote a program that computes primes up to an upper bound of 0xFFFF (the maximum value as can be stored in uint16_t). To reduce time complexity, I used an array that remembers the prime numbers we've already computed and uses only the necessary amount of them to compute the next prime in the sequence. Unfortunately, the space complexity had to increase for the time complexity to decrease; there may yet be a further way to optimize this code, but I'll leave it here for now.
1/18/2023
Bare Metal C
Solved problems 6 and 7. These were very easy, so I spent most of my time making them as clean looking as possible. Problem 7 asked me to write a program that prints only the vowels from a string. I'm pleased to say that after working with ASCII codes so much now, I was able to recall the codes for the vowels, both upper and lowercase, from memory.
C++20 Masterclass
Completed lectures 63 through 66. They were all about "const", "constexpr", and "constinit". I understand const very well at this point: it allows the programmer to make it very clear that the variable should not be altered - in fact, it can't be since the compiler will throw an error if it is altered. CONST makes a variable read-only. CONSTEXPR allows us to specify that a computation should occur at compile time instead of runtime (I still need to better my understanding). CONSTINIT "...ensures that the variable is initialized at compile-time, and that the static initialization order fiasco cannot take place (source). Also, I found an article on geeksforgeeks.org that helps clarify what "constexpr" does and how it is different from "const".
Linux
I wrote a bash script that streamlines the process of updating the driver for the wifi dongle connected to my desktop. Here's the script:
\#!/bin/bash
\# A script that streamlines updating the cudy wifi dongle
cd /home/seandavidreed/cudy_driver/rtl88x2bu_linux
sudo make
sudo make install
sudo modprobe -r 88x2bu
sudo modprobe 88x2bu
1/19/2022
Linux
I wrote another bash script; this one is very simple:
\#!/bin/bash
cd /home/seandavidreed/my\_programs/studentlog4.0
./studentlog
It’s just an easier way to launch my studentlog console application. Now I just open a console and type in studentlog.
C++
I watched this video on the constexpr keyword, and it was very helpful! Here’s the notes:
- Why is constexpr interesting?
- No runtime cost, no need execution time, minimal executable footprint, errors found at compile time, no synchronization concerns.
constexpr int const\_3;
// is interchangeable with
static const int const\_3;
// but constexpr works with float, for example
// while static const does not.
The video had some examples that were beyond my ken, so I skimmed the latter half of it.
1/20/2023
C++20 Masterclass
I completed lectures 67-69. They were on implicit and explicit data conversions, implicit conversions as with:
int sum {};
double x {4.56};
double y {5.67};
sum = x + y; // the value will be truncated and stored in sum as 10
and explicit conversions as with:
int sum {};
double x {4.56};
double y {5.67};
sum = static_cast<int>(x + y); // same result as before, but explicitly so
C++ Practice
I decided to give myself some meaningful programs to write in C++ so I can apply what I'm learning. I've been reading up on the graph data structure, and I found a great resource: this website gave a great demonstration of a graph class in C++. I pretty much copied the code exactly line-by-line, and it improved my understanding. I'll have to keep wrestling with this concept.
1/21/2023
Researching the Graph Data Structure
I didn't get much of a chance today to write code, but I did read up on the graph data structure more. I had to stop myself from feeling discouraged: I was feeling the strain of learning a new concept, and I was tempted to criticize myself for feeling that way. I had to remind myself that learning is always hard, and that I was probably feeling tired from working my regular job.
1/22/2023
Graph Data Structure in C++: adjacency_list1.cpp
I did it! I implemented my own graph class in C++! The example I found on techiedelight was indispensible, but when I implemented my own, I tried to do so by thinking through the logic and syntax myself. Moreover, I wrote the constructor such that the user initializes the graph at runtime. After reading on geeksforgeeks, I was able to understand the graph data structure much better. Also, my mind is much sharper today.
I decided to start including practice programs in this daily log repo. That way I can keep a much clearer record of my progress. Hence, I've added the link to the header of this entry.
GIT
It's settled. I need to become more proficient with git, and that probably entails taking a short class, or watching in-depth tutorial videos. Let me try to outline the problem I faced today:
- Need to clone this repository (programming_log) onto my desktop computer, but I keep getting this error:
Support for password authentication was removed on August 13, 2021. - Try using GCM (git-credential-manager), which I believe I used successfully on my laptop. For some reason, I can't get it working. Even though GCM is configured, running git clone on HTTPS still throws the original error, like gcm is failing to run. Because I'm too fed up to troubleshoot further, I look for other options.
- Try using SSH (Secure Shell Protocol). Following this tutorial, What is a Git SSH Key?, I'm able to create a key-pair on my local machine stored in .ssh in my user directory. The final command,
ssh-add -K /Users/you/.ssh/id_rsa, results in a request for an authenticator pin, which I don't have set up with GitHub, so I ask stackoverflow for help. Turns out I just need to omit-Kfrom the command. - Go to profile, settings, and SSH and GPG Keys. I add new SSH key, but try as I might, I can't seem to get the correct format for the key even though I'm copy-pasting it from .ssh
Key is invalid. You must supply a key in openssh public key format. Turns out I'm using the private key, and I need to use the public key (.pub). After troubleshooting further formatting errors, I succeed. - Create new directory, initialize it as a local repo, and run
git remote add programming_log git@github.com:seandavidreed/programming_log.git. I get this warning:The authenticity of host 'github.com (192.30.252.128)' can't be established. With further digging, I arrive at GitHub Docs from which I learn I can add GitHub public key fingerprints to a file I have to create (known_hosts) in~/home/seandavidreed/.ssh. This resolved the warning. - Run
git fetch, which works, and thengit merge, which doesn't. I getfatal: no remote for the current branch. I find out that since I just initialized this local repo, it doesn't have a real branch,fatal: You are on a branch yet to be born, and it won't until I commit something. I realize I'm doing this all wrong. - Realize that I don't need to create and initialize a local repo; I can just run
git clone git@github.com:seandavidreed/programming_log.git, which is the clone command with SSH. It works and I now have the remote repo on my desktop, from which I am updating this programming_log.
Oh the suffering. Oh the naivete.
Graph Data Structure Again! adjacency_matrix1.cpp
I decided to try my hand at the adjacency matrix representation of a graph. I can see why the adjacency list is more popular. While the matrix is conceptually easier to understand and implement, the list has a significantly reduced space complexity. I could feel the weight of all the space being used as I wrote the program! I suspect I could optimize that space complexity when I refactor.
1/23/2023
Research
I didn't get to do my usual study today, but I did create a new Reddit account with the aim of joining several programming subs, where I can hopefully learn more about building my own projects from the community.
I also created an account with OpenAI playground so I could use chatGPT. I was able to test it out, submitting queries such as "write a graph data structure in C++" and a question related to the beauty industry (that Rachel formulated) that only a professional would know. The AI answered both queries expertly. Even though I know that chatGPT is really only recycling and rehashing content created by humans and shared on the internet, the fact that it does it so well makes me worry for the future of disciplines like programming. I Know my fears are somewhat irrational, but I can't help it!
1/24/2023
Bare Metal C
I read through Chapter six entirely this afternoon. It was on Arrays, Pointers, and Strings, all things I'm well familiar with. Nonetheless, I did have a few takeaways:
- "The size of the pointer depends on the processor type, not the type of data being pointed to. On our STM32 processor, we have 32-bit addresses, so the pointer will be a 32-bit value.
- When initializing a pointer, we specify the data type to which it points (uint32_t *ptr). This does not do anything to the size of the pointer itself, but rather it indicates how the pointer is to be incremented in the case of pointer arithmetic, i.e. (ptr + 1) will move the pointer over by four bytes since a uint32_t is four bytes in size. It will go from 0xFFE0 to 0xFFE4, for example.
I solved programming problems 1 through 3. Number 3 proved to be a most interesting challenge: "Write a program to scan an array for duplicate numbers that may occur anywhere in the array." The first solution that came to mind was brute-force, touching every element and testing it against every other element for a time complexity of O(n^2). For any sufficiently large array, this method is absurd. I thought of other solutions as well, but ultimately I realized that the best thing to do would be to sort the array beforehand. Naturally, I turned to merge sort. Loosely referencing an old implementation of mine, I wrote another mergesort algo, and in the process, I found that with a few tweaks the mergesort algorithm itself could count the number of duplicates while sorting the array. Here's what I wrote:
/*
* duplicates2.c
*
* Created on: Jan 24, 2023
* Author: seandavidreed
*/
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <math.h>
#include <time.h>
#define TYPE uint16_t
// ARRAY_SIZE cannot be a value larger than can be held
// by the fixed-width data type above
#define ARRAY_SIZE 1000
void initRandomArray(int *arr, int size) {
srand(time(NULL));
for (TYPE i = 0; i < size; ++i) {
arr[i] = rand() % (int)pow(2.0, sizeof(TYPE) * 8.0);
}
}
void mergeSort(int *arr, int *temp, int i, int j, int *count) {
// base case
if (i >= j) return;
// recursive case
int mid = (i + j) / 2;
mergeSort(arr, temp, i, mid, count);
mergeSort(arr, temp, mid + 1, j, count);
int lptr = i;
int rptr = mid + 1;
int k;
for (k = i; k <= j; ++k) {
if (lptr == mid + 1) temp[k] = arr[rptr++];
else if (rptr == j + 1) temp[k] = arr[lptr++];
else if (arr[lptr] == arr[rptr]) {
temp[k] = arr[lptr++];
(*count)++;
}
else if (arr[lptr] < arr[rptr]) temp[k] = arr[lptr++];
else temp[k] = arr[rptr++];
}
for (k = i; k <= j; ++k) {
arr[k] = temp[k];
}
}
void printArray(int *arr, int size) {
for (TYPE i = 0; i < size; ++i) {
printf("%d ", arr[i]);
}
printf("\n");
}
int main() {
int array[ARRAY_SIZE], temp[ARRAY_SIZE];
int count = 0;
initRandomArray(array, ARRAY_SIZE);
printArray(array, ARRAY_SIZE);
mergeSort(array, temp, 0, ARRAY_SIZE - 1, &count);
printArray(array, ARRAY_SIZE);
printf("Number of Duplicates: %d\n", count);
return 0;
}
1/25/2023
Bare Metal C
Finished the last two problems in chapter 6, numbers 4 and 5. They were pretty easy. However, I ran into a snag on problem 5; I was trying to pass a char pointer as an argument to my void capitalize(char *str) function, which capitalizes the first character of every word beginning with a letter. The problem is when a string is declared like this char *str = "This is a string.";, the string is not mutable. I needed to instead declare it like so, char str[] = "This is a string.";. Though I've looked into this topic many times, I still find the terminology somewhat abstruse. However, the concept is intact. Here's a resource on the subject: Character Strings in C.
Hardware
Woohoo! I successfully test my PIR motion sensor from adafruit. It’s a small feat, but I’m proud of it nonetheless. Here’s a picture: picture. I sorted out the configuration by consulting this documentation
C++20 Masterclass
Made my cpp20-masterclass projects folder into a git repository. Now I can work on these projects on my Linux desktop as well! I had to make some adjustments in the .json files, but it was relatively simple. I noticed that if I don’t have the C/C++ Microsoft extension installed, then VSCode won’t recognize the the key-value “type”: “cppbuild” in tasks.json.
1/26/2023
C++20 Masterclass
Completed 72 - 74. All on bitwise operators. The demonstration of data loss via shifting bits left or right was most helpful.
1/27/2023
C++20 Masterclass
Completed 75 and 76. It was mostly review, but I appreciated the way the information was presented. We were able to clearly demonstrate the behavior of the bitwise logical operators.
Data Structures and Algorithms
I need to study DSA alongside my C++ study; that way I have practice problems to tackle with the language. I'm consulting an article on geeksforgeeks to get a better understanding of DSA. After the overview of Data Structures and Algos, we get into time and space complexity. I decided to plot each complexity function on a graph on desmos. Below is the image I created:

In order from worst to best: O(n!), O(2^n), O(n^2), O(nlogn), O(n), O(logn), O(1).
I also consulted a list of examples for each complexity on stackoverflow.
I tried in vain today to create a circular linked list. I had the right ideas in mind, but my brain was simply too foggy and weary to deliver. Oh well. I'll try again tomorrow.
1/28/2023

Data Structures in C++ Circular Linked List
I successfully implemented the circular linked list! It was actually rather a challenge to wrap my head around it, but in the end I was able to reason it out. I intend to keep studying various data structures and algorithms using C++ and roughly following the image above. I'm reacquainting myself with all things linked lists, and then I'll move on the the matrix and see if there's anything I'm missing there. Moreover, I'd like to see some real life applications for these data structures. For instance, I want to see a tangible use of the circular linked list. Perhaps tomorrow I will search for one.
1/29/2023
Data Structures in C++ Circular Linked List
After yesterday's successful implementation of the circular linked list, I went on geeksforgeeks and browsed the practice problems. I found this problem, which enjoined me to write a funtion that splits a circular linked list into two circular linked lists. The problem is listed as medium difficulty, but I made it even harder on myself: I could have written a function that merely copies each half of the linked lists into two new linked lists, but I didn't want to increase time and space complexity that much. I wanted to find a way to manipulate the pointers in the existing linked list and create two lists by simply redirecting the node pointers diametrically-opposed to the head pointer, one to the head itself, and the other to become a new head that then points back to head->previous. Observe the graphic:

Moreover, I wanted to create this split function, which I called void mitosis(CircleLink& newList), as a method inside the CircleLink class. It all works! I had to suffer to get it to work, and I found that my main problem was in reassigning the pointers; I had a hard time keeping it straight which one was pointing where as I redirected them until I created more pointers to hold onto important addresses. Therefore, I succeeded in my initial design, but it may not be worth the amount of extra space I needed for each pointer. I'll be happy with it for now.
1/31/2023
Data Structures in C++
Deletion in a Circular Linked List
Yesterday after a busy day outside, I wrote a delete node function, and it wasn't working. For the life of me I couldn't figure it out: I thought it was another issue with reassigning the pointer addresses, but this morning I opened up the code and the error stared me in the face:
void deleteNode(unsigned value) {
Node *ptr = head;
for (int i = 0; i < numNodes; ++i) {
if (ptr->value = value) {
ptr->previous->next = ptr->next;
ptr->next->previous = ptr->previous;
delete ptr;
--numNodes;
return;
}
ptr = ptr->next;
}
}
I clumsily used an assignment operator instead of an equality operator in the if condition. That was all that was wrong!
I started working on a C++ program to sort a matrix, and I found myself perplexed at some of the differences between pointers and arrays. I've learned this stuff before, but it's likely there's a finer-grain understanding I've yet to achieve; I read this article, which helped to clarify some of the distinctions between them. The following is a quote from the article:
A common misconception is that an array and a pointer are completely interchangeable. An array name is not a pointer. Although an array name can be treated as a pointer at times, and array notation can be used with pointers, they are distinct and cannot always be used in place of each other. Understanding this difference will help you avoid incorrect use of these notations. For example, although the name of an array used by itself will return the array’s address, we cannot use the name by itself as the target of an assignment.
Reading this article brought to mind an old question I've had, namely "what does it mean that an array 'decays' into a pointer when it is passed to a function?" After searching around on the internet, I got a good grasp of the concept of array decay. The quote above holds the key: a pointer and an array name are not identical. The array name, like the pointer, yields the address of the first element, but it also contains with it the sizeof the whole array, which can be accessed by the sizeof() operator. Contrarily, if the sizeof() operator is run on a pointer, the size of the pointer will be returned. When an array is passed to a function, a pointer to the address held in the array name is passed instead. This can be circumvented by passing the array by reference. Observe the following examples:
// This first example will result in pointer decay
// since the array is passed by value.
#include <iostream>
unsigned long foo(int arr[]) {
return sizeof(arr);
}
int main() {
int arr[10] = {};
std::cout << sizeof(arr) << std::endl; // prints 40
std::cout << foo(arr) << std::endl; // prints 8 (on 64-bit machine)
return 0;
}
// This example won't result in pointer decay
// since the array is passed by reference.
// This can also be accomplished with
// unsigned long foo(int (*arr)[10])
#include <iostream>
unsigned long foo(int (&arr)[10]) {
return sizeof(arr);
}
int main() {
int arr[10] = {};
std::cout << sizeof(arr) << std::endl; // prints 40
std::cout << foo(arr) << std::endl; // prints 40
return 0;
}
2/1/2023
Data Structures in C++ Sort A Matrix
Today I completed the sort algorithm for a matrix. I implemented Selection Sort, which has time complexities of O(n^2) and $\Omega$(n^2). The initial challenge I faced was how to iterate through the matrix in a way that worked for selection sort; I needed to maintain two sub-arrays inside a matrix. The solution was to treat the matrix as an ordinary one-dimensional array. By including the printAddresses() function in my class Matrix, I was able to see how the arrays were arranged in memory. The addresses in a given row were of course spaced by 4 bytes, the typical width of an int. However, between one row and another, there was a buffer of 16 bytes. My naive hope that they would somehow be contiguous was dashed, so I decided to iterate through the matrix traditionally, with i and j. However, I made the inner loop like this:
while (i < _rows) {
if (matrix[i][j] < matrix[iSmall][jSmall]) {
iSmall = i;
jSmall = j;
changes = 1;
}
++j;
if (j == _cols) {
++i;
j = 0;
}
}
The bit at the end below ++j allowed me to iterate through each row as if they were contiguous. Conceptualizing the matrix as an ordinary array was the key.
The first iteration I got working included the swap operations in the inner while loop. This meant that worst-case scenario, the number of swaps performed would be O(n^2). However, when I looked it up, the internet kept saying that there should be at worst O(n) swaps. After a quick look on stackoverflow, I learned that I needed to put the swap operations in the outer while loop below the inner loop. In the inner loop, I then needed to keep track of the indices of the current smallest element, not the element itself.
For fun, I analyzed the difference in runtime between these two implementations:
O(n^2) swaps vs O(n) swaps
.0126s .0115s
The matrix I used to get these average figures was rather small, hence the one millisecond difference. If the dataset were much larger, the runtime difference would likely be much more noticeable. I had fun with this problem!
C++20 Masterclass
Completed lecture 77 on bitmasks. This is the very same content I've been reviewing in Bare Metal C, which I'd like to get back to soon. I'm eager for the time when I can build confidently with C++.
2/2/2023
C++20 Masterclass
Completed lectures 78 and 79, which concludes Section 12 on Bitwise Operators. I especially liked the example in 79, where we packed RGB values into one 4-byte unsigned int type. With this method, there is one unused byte, but this is still far more efficient than using 12 bytes (in the case of 3 ints) for values that span 0 to 255.
Data Structures in C++ Stack
Running down the list of Data Structures on geeksforgeeks, I implemented a Stack class in C++. Compared to other data structures, this one is fairly easy to build.
STM32cubeIDE
I downloaded this IDE today with the hopes of using it to program the Raspberry Pico and the Nucleo F030r8 development board. I'm really eager to get a true embedded project off the ground!
2/3/2023
C++20 Masterclass
Completed lectures 81 through 84. There was not much new here, so I watched the videos at increased speed. I didn’t have time for much else today!
2/4/2023
Bare Metal C
I completed chapter 7, which was all about Local Variables and Procedures. The bits on local variables helped sharpen my understanding of static allocation, which occurs at compile time and is hard-coded into a programs binaries before it even runs. That is much clearer now. Using the GDB debugger in STM32 Workbench, we were able to observe function calls being added to the stack. This was especially interesting in the case of the recursive factorial function: I witnessed the stack grow to the necessary size to initiate the functions base case, and then shrink as each stack frame resolved and was destroyed. Tomorrow, I plan to do the practice problems.
2/5/2023
Bare Metal C
I Solved practice problem 3 in chapter 7. It was the classic recursive fibonacci function problem. I remember this being difficult to write the first time I tried it early last year, but now it was extremely easy; I just needed to refresh myself on the fibonacci sequence formula.
#include <stdio.h>
#include <stdlib.h>
unsigned int fibonacci (unsigned const int n) {
// Base Case
if (n == 1) return 0;
else if (n == 2) return 1;
// Recursive Case
return fibonacci(n - 1) + fibonacci(n - 2);
}
int main() {
printf("%u\n", fibonacci(5));
return 0;
}
Exploring the Nucleo Board and STM32 Cube IDE On My Own!
My goal is to connect the PIR (Pyroelectric InfraRed) Motion Sensor I got from Adafruit to my Nucleo F030R8 development board.
-
First, I wanted to check the power pins on the development board to see if I needed to initialize them. I connected test leads to the 3V3 and GND pins and used my multimeter to read the voltage, which indeed was 3.3 volts.
-
Next, I consulted the Bare Metal C book, from which I refreshed myself on LED initialization:
LED2_GPIO_CLK_ENABLE(); GPIO_InitTypeDef GPIO_InitStruct; GPIO_InitStruct.Pin = LED2_PIN; GPIO_InitStruct.Mode = GPIO_MODE_OUTPUT_PP; GPIO_InitStruct.Pull = GPIO_PULLUP; GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_HIGH; HAL_GPIO_Init(LED2_GPIO_PORT, &GPIO_LedInit);I placed this code inside the comments:
/* USER CODE BEGIN Init */ /* USER CODE END Init */found inside the main.c source file.
-
I needed to understand the
LED2_GPIO_CLK_ENABLE();macro so I could ostensibly apply the same thing to my motion sensor peripheral. I highlighted the statement, and selected "search text" and "workspace". The search did not reveal anything I needed. -
Explored the
stm32f0xx_hal_gpio.hlibrary to find the preprocessor definitions for the GPIO pins. I'm usingGPIO_PIN_2. -
Explored the
stm32f0xx_hal_conf.hlibrary and found an include forstm32f0xx_hal_rcc.h. I found that "RCC" stands for Reset Clock Control." I thought maybe I could find out what the correctCLK_ENABLE()macro would be for my motion sensor - to no avail. I decided to guess that it would be calledPIN_2_GPIO_CLK_ENABLE();. -
When I tried to build the project, I found that
LED2_GPIO_CLK_ENABLE(); PIN2_GPIO_CLK_ENABLE(); LED2_PIN; LED2_GPIO_PORT; PIN2_GPIO_PORT;were all flagged as implicit declarations. This means that there is a library that STM32 System Workbench includes by default and that STM32 Cube IDE does not. My next step is to retry everything back in System Workbench. I really just want to wrap my head around all this!
-
Found the solution! I copied all my code over to System Workbench and right away I noticed a library that was not included over at Cube IDE,
stm32f0xx_nucleo.h. Opening this library, I found several aliases; for example.GPIO_PIN_5is aliased toLED2_PIN, andGPIOAis aliased toLED2_GPIO_PORT.__HAL_RCC_GPIOA_CLK_ENABLE()is aliased toLED2_GPIO_CLK_ENABLE(). As I looked through the different macros, I came across these ones:#define NUCLEO_SPIx_SCK_GPIO_PORT GPIOA #define NUCLEO_SPIx_SCK_PIN GPIO_PIN_5 #define NUCLEO_SPIx_SCK_GPIO_CLK_ENABLE() __HAL_RCC_GPIOA_CLK_ENABLE()Looking at the development board, I saw that pin 13 was also named
SCK. I divined that I could connect my PIR Motion Sensor to this pin and use the macros above, and it worked! Here's a picture:

2/6/2023
Computing Technology Series on YouTube
This series is all about the evolution of the CPU from the Intel 4004 onward. I'm taking notes in a separate file for this one since I expect to write a lot, and I don't want to clutter up this log! Here's the link.
Raspberry Pi Pico
Last week I found a video that would show me how to start using the Raspberry Pi Pico with C/C++. Today, I followed along with the video and got everything working nicely. I can tell this microcontroller will be much easier to work with than the Nucleo F030R8. Therefore, I'll use it to learn some more beginner embedded techniques. I still would much like to get good at using the Nucleo board too. Anyhow, this video showed me how to write and run an led-blinking program on the pico. It also covered how to use a core for each led blinking operation; I thought that was pretty fascinating and I'm keen on learning more about it.
2/7/2023
Raspberry Pi Pico
I decided to set up the C/C++ sdk for the Pico on my desktop computer as well. This time I followed the official documentation. I left off at Chapter 4 - I intend to work my way through the whole document.
Bare Metal C
I'm in Chapter 8, which is on Complex Data Types (I can see that this chapter plus the next two will be quite important and will likely present new concepts). I read through the first part of this chapter regarding enums and a neat preprocessor trick that can be done with them. Here it is below for reference (I copied this from the book):
#define COLOR_LIST \
DEFINE_ITEM(COLOR_RED), \
DEFINE_ITEM(COLOR_BLUE), \
DEFINE_ITEM(COLOR_GREEN)
#define DEFINE_ITEM(X) X
enum colorType {
COLOR_LIST
};
#undef DEFINE_ITEM
#define DEFINE_ITEM(X) #X
static const char* colorNames[] = {
COLOR_LIST
};
#undef DEFINE_ITEM
After thinking through this process for a moment, it clicked, and I could see how useful it will be. I'll be working my way slowly through this chapter to absorb as much as I can.
2/8/2023
Bare Metal C
Chapter 8 new-to-me concepts in my own words:
-
The Enum data type is new to me, as outlined above.
-
The system architecture defines, among other things, the size of data that is to be passed along the address and data buses. In a 32-bit system, we essentially have a 32-lane superhighway for the data bus and a 32-lane superhighway for the address bus. Therefore, if we have a struct in memory that is 6 bytes in size, when the CPU performs a
fetchfrom RAM, it will first fetch 4 bytes (32 bits) of the struct via the data bus, and then it will fetch the remaining 2 bytes along with 2 bytes of padding (32 bits in total) - this padding is defined by the compiler, which prepares the struct according to the system architecture. -
When a structure is initialized, we can declare a struct name or a variable or both. If a struct is to be used only once, it makes sense to declare it with a variable and without a name:
struct { int dosage; int drug; } myPrescription;I won't have to declare this struct in main since it is declared here. We can declare both a name and a variable:
struct prescription { int dosage; int drug; } myPrescription; -
In the unions section, the concept of Endianness is touched on (without being named). It is another facet of the system architecture and it defines how a
wordis stored, either from lowest-order to highest-order byte, as in little Endian, or vice versa, as in big Endian. Little Endian is the most common since it allows a givenwordto be read the same regardless of the number of bits read:0x13 will be stored 1300 0000 0000 0000 in a little endian, 64-bit machine. If the same value were read as 32-bit 1300 0000, it will still read 0x13.
The term Endianness is derived from Gulliver's Travels, in which there are two factions of Lilliputians, one which cracks hard-boiled eggs from the big end, and the other which cracks them from the little end.
I left off at Creating A Custom Type, which I will pick up perhaps tomorrow!
Raspberry Pi Pico
I decided to test out my PIR Motion Sensor with the pico, and writing the code proved to be much simpler than that of the Nucleo board. That doesn't surprise me though since I believe the Pico is designed to hold your hand a little more than the Nucleo F030R8. I got everything wired up on the breadboard, but then I noticed the sensor seemed too sensitive: it would trigger after a movement, but then it would keep triggering for an extended period of time without any movement. I proved this by walked out of the room and observing the LED via a mirror - it still flashed. I tried many things to troubleshoot; I thought maybe the signal was too strong so I added some resistors, but I realize this is a naive notion. After many hopeless attempts, I found the answer online; a reply on stackexchange suggested that Vcc should not be 3v3 but at least 5v. I had the sensor drawing power from 3v3, which evidently causes retriggering. When I changed the the power to 5v, the sensor began working perfectly!

Here's the code I wrote - I took the opportunity to practice with enums!
#include <stdio.h>
#include "pico/stdlib.h"
#include "hardware/gpio.h"
#include "pico/binary_info.h"
enum GPIO_IN_USE {
PIR_LED = 14,
PIR_SENSOR = 16
};
int main() {
bi_decl(bi_program_description("This is a test binary"));
bi_decl(bi_1pin_with_name(PIR_LED, "Peripheral LED"));
stdio_init_all();
gpio_init(PIR_LED);
gpio_init(PIR_SENSOR);
gpio_set_dir(PIR_LED, 1);
gpio_set_dir(PIR_SENSOR, 0);
while (1) {
if (gpio_get(PIR_SENSOR)) {
gpio_put(PIR_LED, 1);
sleep_ms(200);
gpio_put(PIR_LED, 0);
sleep_ms(200);
gpio_put(PIR_LED, 1);
sleep_ms(200);
gpio_put(PIR_LED, 0);
}
}
}
2/9/2023
Bare Metal C
I studied the design pattern found in the Creating a Custom Type section and I think it's pretty cool. I went ahead and replicated the program, adding my own touches, to fully understand the logic behind it. Here is the final product. I like the clever use of a union within a structure, which allows a structure to have a dynamic member. The addition of the enum is a nice touch too as it makes the code much more readable. It also allows the drawShape() function to recognize which shape is being passed in by checking the enum shapeType type member.
I wanted to practice with enums, but I found myself practicing with function pointers instead. I want to get a better grasp on their usage. Here's my silly little programs: func_ptr.c.
2/10/2023
Algorithms in C++ merge_sort
I wanted to practice with function pointers today, so I thought I'd try to implement a callback function for a sorting algorithm, the way Quick Sort is often implemented. I chose to build a Merge Sort Algo since it's kinda my pet algo at this point. I have studied it enough that I can now code it simply by thinking through the logic! It's a great feeling. I wrote a merge sort algo that works great, but I found myself unable to add a function pointer into the mix. I still don't understand their import enough to add them into my thought process. Oh well, I guess I got more practice with merge sort today.
I'm so glad I got back into Reddit again. I'm finding countless helpful tips on the r/embedded sub. For instance, today I found the Fastbit series on MCUs, which are available on Udemy, by reading this post. I ended up purchasing the class for cheap and I intend to start it once I complete Bare Metal C! Things to look forward to.
2/11/2023
C++20 Masterclass
I watched lectures 85 through 89 today. The majority were simply review, e.g. else and switch statements, ternary operator, and using integral types as booleans. There was a topic that was rather helpful: Short Circuit Evaluations. When a compound conditional statement with logical operators of one type is evaluated, only the information that is necessary to establish the condition is read. For example:
// The program will stop checking the conditions after the "false"
if (true && false && true && true) {
// Some code
}
The presence of that single false renders the whole statement false regardless of the following conditions, so the program disregards them. This is an important process to know because we can take advantage of it. We can write compound conditional statements with the most decisive conditions first. If we are writing a statement like the one above, we should put the condition most likely to be false first.
Algorithms in C++ mergeSort1000
I worked on my merge sort algorithm; I wanted to find a way to eliminate the need for an auxilliary array mergeSort(const unsigned int i, const unsigned int j, int arr[], int aux[]). Initially, I thought that an auxilliary array was being automatically allocated for every function call - such an operation would be extremely bloated, requiring something like nlog(n) number of arrays. This is not the case however. The initial array passed to the function decays into a pointer which is then passed again and again to the function recursively, so it seems there would be nlog(n) number of automatically allocated pointers instead. By removing int aux[] from the function parameters and replacing it with static int aux[1000] inside the mergeSort function, I simplified the use of the function, but I limited the size of array it can accomodate. A statically allocated array cannot have a variable size since it is baked into the program binaries. The statically-allocated auxilliary array is only defined once, at compile time, so even though the mergesort function behaves recursively, the auxilliary array will not. It's unclear whether I optimized the algorithm with this change, but I believe I did make it prettier, if that's worth anything!
2/13/2023
Watching Videos about AI
Following a brief conversation with Rachel's mom in which she mentioned a Google engineer that claims LaMDA is sentient, I watched the following videos:
- Google Engineer on His Sentient AI Claim
- No, it’s not sentient - Computerphile
- But How Does ChatGPT Actually Work?
Video three deviates from the topics of one and two a little bit; the first two regard LaMDA by Google, not chatGPT. What did I learn from these? First, the Google engineer is not claiming that the AI is sentient—he makes it clear that sentience is I’ll-defined anyways. As someone said in the comments, the attention-grabbing headline has likely more to do with the news outlets tactics than the engineer’s actual perspective. Second, I learned a little about transformer architecture, emphasis on little. I’m very intrigued by the developments in AI, but I know I need to keep on my current track toward embedded systems. Nevertheless, I’ll continue to gain surface knowledge on AI until such time that I can learn more deeply.
Bare Metal C
I found the Structures and Embedded Programming section informative. It mentioned the Small Computer System Interface (SCSI), which is a standardized way of transferring data to and from devices (Est. 1986). The standard uses a command block, which was only 6 bytes at first but is now 32, to specify the address and size of the data and the opcode of the operation to be performed on it. Following the read10 standard, we made a command block using a struct:
#include <stdio.h>
#include <stdint.h>
#include <assert.h>
struct read10 {
uint8_t opCode; // Op code for read
uint8_t flags; // Flag bits
uint32_t lba; // Logical block address
uint8_t group; // Command group
uint16_t transferLength; // Length of the data to read
uint8_t control; // Control bits, the NACA being the only one defined
};
int main() {
printf(“%ul”, sizeof(struct read10));
assert(sizeof(struct read10) == 10);
return 0;
}
The printf statement yielded 16, and the assert statement terminated the program since 16 != 10. In the book’s example, the program yielded 12 bytes for the size of struct read10. In both cases, the compiler automatically pads the structure if any of the data are unaligned. For instance, the books example is from a 32-bit system, so the data in the struct will be read in that word size, which makes uint32_t lba unaligned since its address is not offset by 4 bytes from the address of uint8_t opCode. The compiler adds 2-bytes padding between ‘uint8_t flagsanduint32_t lba` and the data is now aligned to the word size.
In my own example, I’m working with 64-bit system architecture, so the compiler did this:
struct read10 {
uint8_t opCode;
/* 3 bytes padding added */
uint8_t flags;
/* 3 bytes padding added */
uint32_t lba;
uint8_t group;
uint16_t transferLength;
uint8_t control;
};
I have to say that, after looking through the assembly code, I was a little perplexed at the way the data was moved, but I think I got the gist of what went on in the code block above.
2/14/2023
Bare Metal C fraction.c
Wow, I had way too much fun with Problem 1 of Chapter 8, and I learned a ton. The problem is written as follows:
"Create a structure to hold a fraction. Then create procedures that add, subtract, multiply, and divide fractions. The fractions should be stored in normalized form. In other words, 2/4 should be stored as 1/2."
Designing the struct was easy enough. Things got interesting when I began working on the fraction add(fraction *addend1, fraction *addend2) function. The initial arithmetic on the numerators and denominators was fun to implement. I wanted the code to be syntactically sugary and tight; I'm happy with what I got. I quickly realized that the second step, reducing the fraction to its simplest form, would need to be repeated for each arithmetical function (add, subtract, multiply, divide), so I created a separate function, void reduce(function *reduce). I couldn't find a better way to factor out the fraction besides using nested loops. I take half of the smaller term and iterate from 2 up to that number checking which divisors will leave no remainders. As long as a given divisor keeps dividing evenly, the function remains in an inner while loop.
Everything worked just fine until I needed to work with negative values; finding the smaller term becomes problematic because a negative number is always smaller than a positive number. What I really needed was the number that is closest to zero - I needed the absolute value. I didn't want to use the math.h library function, abs(). I thought about using bitwise operations with bitmasks. This proved to be the right idea, but I couldn't get the right implementation. I wanted one bitmask to both remove the sign from negative numbers and leave positive numbers unaffected. I caved and searched for the answer. These were the two sources I found:
Compute the Integer Absolute Value Without Branching
Bit Twiddling Hacks
At first, I was so baffled at how these functions worked:
int v; // we want to find the absolute value of v
unsigned int r; // the result goes here
int const mask = v >> sizeof(int) * CHAR_BIT - 1;
r = (v ^ mask) - mask;
I presumed the mask to be equal to 0x1 by the end of the operation, so I didn't see how this worked, yet it did. This page in the Right Shifts section cleared it up: when a right shift is performed on a negative integer, 1's are propagated to the right:
signed short int someValue = 0b1000000'00100000;
someValue >> 1;
// 0b11000000'00010000
someValue >> 4;
// 0b11111100'00000001
someValue >> 4;
// 0b11111111'11000000
This is reasonable since the right shift is supposed to reduce the magnitude of a value by half for each move. As more 1’s propagate, the negative value approaches 0. Apparently some processor architectures define a different behavior for right shifting negative integers, presumably causing the magnitude of the negative value to double with each right shift.
2/15/2023
Bare Metal C
- car_struct.c - Wrote a program for problem 2, and I added more functionality than was required for the sake of practice. The main goal here was to implement a car struct that contains a union for two structs of vehicle types, electric and gas. In addition to completing this, I implemented the enum preprocessor trick outlined on 2/6/2023. Additionally, I added a color member to the struct that stores RGB values in a
uint32_ttype. For this member, I wrote functions that read and write from the member with bitwise or and shift operations. I had a lot of fun doing it! - acmeTrafficSignal.c - Worked on this one for a good while. I couldn't understand why the problem wanted me to organize the program the way it did (I did take some liberties, like using function pointers and adding my own functions). In the end, I decided to roll with it. It was good practice for enums, unions, and function pointers.
2/16/2023
C++20 Masterclass
I completed lectures 90 through 92, and there was some material that was new to me:
if constexpr (condition) {}if constexpr allows us to evaluate an if condition at compile time provided the condition itself isconstorconstexpr. I can see this being very useful for situations where a user needs to be able to modify a constant value at the top of a program and the runtime needs to remain unaffected. The constant value might be tied to several conditional statements throughout a library or API, for instance, and if the calculations are heavy,if constexprwill make sure that the runtime is not affected by them.if (int someVar {10}; otherVar) {}This is also really handy. Now we can declare a variable only for the scope of a given if condition. This allows us to keep from cluttering up the namespace, which is especially important if the program is very large.switch int someVar {10}; otherVar) {}This works essentially the same way the if with initializer works.
2/17/2023
Bare Metal C
I started in on Chapter 9, Serial Output on the STM. Before reading the majority of this chapter, I didn't really have an idea of serial I/O. Now I undertstand that serial I/O in a general sense is the pushing of bits in series in what's called a stream. I imagine that the opposite of serial would be parallel, sort of like in electric circuits. When a CPU fetches data from RAM, I imagine the data could be said to be received via the data bus in parallel; there are multiple lanes in the superhighway delivering the data in multiple streams. Disclaimer: I might be making stuff up here. Really, I'm only trying to help myself conceptualize the process of Serial I/O. For serial communication with a microcontroller, we have to access RX (receiver) and TX (transmitter) pins. In the case of the NUCLEO board, the TX and RX pins are already wired up for us, so we don't need to connect any additional jumper cables.
I especially enjoyed reading the section A Brief History of Serial Communications, in which we are taken from the telegraph to the teletype to the computer. Through each advancement, serial communications technologies have remained relatively the same, except that they have increased in speed (baudrate, which is bits per second). In this section, there is a subsection, Line Endings, I found very interesting. Here's a direct quote:
--Begin Quote--
If you sent a character immediately after the carriage return, you'd get a blurred blob printed in the middle of the line as the printhead tried to print while moving.
The teletype people solved this issue by making the end of a line two characters. The first, the carriage return, moved the print head to position 1. The second, the line feed, moved the paper up one line. Since the line feed didn't print anything on the paper, the fact that is was done while the printhead was flying to the left didn't matter.
However, when computers came out, storage cost a lot of money (hundreds of dollars per byte), so storing two characters for an end of line was costly. The people who created Unix, the inspiration for Linux, decided to use the line feed (\n) character only. Apple decided to use the carriage return (\r) only, and Microsoft decided to use both the carriage return and the line feed (\r\n) for its line ending.
C automatically handles the different types of newlines in the system library, but only when you use the system library. If you are doing it yourself, ... you must write out the full end-of-line sequence (\r\n).
--End Quote--
More useful bits
- UART stands for Universal Asynchronous Receiver-Transmitter.
- USART stands for Universal Synchronous/Asynchronous Receiver-Transmitter.
- In synchronous serial communication, the transmitter continuously sends out characters even when idle to maintain the synchronization between the transmitter and receiver clocks.
- In asynchronous serial communication, the transmitter only sends characters when there is something to send. This form is used when it is reasonable to assume that the transmitter and receiver clocks can stay synchronized on their own.
2/18/2023
Bare Metal C
I finished up Chapter 9 today. At first I was a little displeased by the use of copy code to test out the USART, but my perspective changed when I got to the practice problems at the end of the chapter. These problems helped me to dig through the program and its included libraries and understand it better.
-
For problem 2, I was charged with "...changing the configuration so that you send 7 data bits and even parity (instead of 8 data bits, no parity)." The first step was to understand the function of the parity bit. Parity in mathematics is the even/odd quality of a number. In embedded programmin, a parity bit is used for error-checking. The error-checking method is established as either even parity or odd parity. In the case of even parity, the parity bit is set to 1 whenever there is an odd number of 1's in the 7 data bits and it is set to 0 when there is an even number. This ensures that when the data frame is transmitted, it will have an even number of 1 bits. If when it is received there is an odd number of bits, the receiving register will know that the data has been corrupted and it won't accept it. Odd parity works the same way but opposite.
- Here's what I did to solve this problem: I went into the
void uart2_Init(void)function and changeduartHandle.Init.Parity = UART_PARITY_NONEtouartHandle.Init.Parity = UART_PARITY_EVEN. I found the correct macro by right-clicking onUART_PARITY_NONEand selecting "Open Declaration". This change causedHello World!to look something like thisHello??orl?!. The space, 'W', and 'd' all have an odd number of 1 bits, so they were modified and thrown out of the range of printable ASCII characters.
- Here's what I did to solve this problem: I went into the
-
Problem 3 was about adding flow control to thr program to allow the user to start and stop the printing of
Hello World!. To solve this, I once again selectes some codeuartHandle.Init.HwFlwCtl = UART_HWCONTROL_NONEand selected "Open Declaration". There I found theUART_HWCONTROL_RTS_CTSmacro, which I deduced to be the value I needed. -
Problem 4 was certainly the most challenging, but with more browsing declarations and reading the documentation on character input, I was able to work out how to change the
myPutChar()function into a semi-functionalmyGetChar()function. The main takeaway from the documentation was how to use the RDR and RXNE variables.
2/19/2023
Today, I sat down to work on my programming, and I found myself feeling bored. I knew it was not the act of programming itself, but the lack of a project toward which I could direct my learning efforts. I’m glad to chip away at classes such as C++20 Masterclass, Bare Metal C, and eventually Mastering Microcontroller and Embedded Driver Development, but I need a personal project as well, like I had with studentlog and Inventory Manager.
I began brainstorming. How could I start a project that would have personal significance, practicability, and that would help solidify what I’m learning? Once again, synths and audio came to mind. After roaming the internet, I found this site, madewithwebassembly.com. After looking at some of the projects, I’ve decided to try to build a web application that can generate audio controlled by hand gestures! Since this will likely be a large project, I’ve created a separate markdown file to document the research and build process. Here it is: Gesture Midi Controller.
2/20/2023
Spent pretty much all of today working on my Gesture Midi Controller project. Though the project has yet to fully take shape, I'm getting myself prepared by learning about the SFML library and about how sound is represented digitally. Gesture Midi Controller
2/21/2023
Gesture Midi Controller Project
2/22/2023
Gesture Midi Controller Project
Once again, I spent all my time on this one. The benefits of doing this project are tremendous. I've learned so much more about C++ simply using it here (this should be obvious). Here's a few things of which I've gained a grasp: function pointers, constexpr, namespaces, short circuit evaluations (or something like it - this refers to the control flow manipulation I did with the if-else statements, which I describe in the project log), and of course, the SFML library. Of course, I'm not done exploring this library, nor building this project. I'm just getting started!
2/23/2023
Personal Website
After a hiatus, I finally got back to this project. Late last year, I set up a GitHub Pages website using Beautiful Jekyll, a template built with Jekyll static site generator. At the time, I had other projects going on, so even though the setup looked easy, I remember being in a hurry and failing to be properly assiduous. Now, returning to this project, it's much easier to sort out. I'm slowly building my site into a personal resume. I intend to display this programming log, any blog posts I write, and my projects (hopefully I can even link in a WASM page or two where my programs actually run in the browser).
I did run into some hiccups today. I uploaded the programming_log folder to the Github Pages repo and it threw an error, which I overlooked. Subsequently, any changes I made to the websites aesthetic failed to propagate. At the end of the day, I found it was because the size of the programming_log folder was too large. Evidently it was halting any further changes to the repo.
2/24/2023
Personal Website
I’m anxious to get this site up and running so I can start showcasing my work, but it’s been nothing but headaches so far! I’ve been committed to using Jekyll for the build, and yet so many templates I’ve tried have been convoluted in their implementation. I think I’ve finally found the one I’ll stick with; I’ve already made several modifications to it. Hopefully I can be done with this effort soon so I can get back to embedded systems and C++ programming.
2/25/2023
Personal Website
Well I did it; I made this programming-log repository public so I could link to it from my website. Speaking of my website, I think I've settled on the right template. I'm finding it much easier to modify according to my needs than other templates I tried. I've also added a projects page where I will place links and descriptions for my most significant projects.
2/26/2023
Personal Website
Today, I made my student-log repository public so that I could link it to my website. Before making it public, I went through and cleaned it of any information, i.e. student info, that I inadvertently included in my commits last year: I was only just getting started with git. To do this, I simply removed the .git and .gitignore files from the local directory, deleted the corresponding remote branch, and reinitialized the local directory and pushed it to a new branch.
2/27/2023
Gesture Midi Controller
Goal: to create a class for different tuning temperaments. In this class, I included my original justIntonation function and a new equalTemperament function. To accomplish this, I needed to learn how to declare a class in a header file and define the class in the related source file. I found this resource helpful.
2/28/2023
Bare Metal C
I'm on Chapter 10, Interrupts. There is a lot of technical jargon in this section, and I've not even finished reading it! I read half the chapter and implemented the example program today. Here's my key takeaways:
- Polling and Interrupts are the two main methods for handling I/O. Polling is easy to understand and implement but suffers in efficiency; Interrupts are hard to understand and implement but are efficient. In my estimation, one is not ubiquitously better than the other. Rather, Polling is useful when a process is guaranteed to happen frequently. Interrupts are useful when a process is going to happen semi-infrequently. This is a gross simplification, but the general logic makes sense and helps reinforce the concept.
- Important Acronyms:
- TDR - Transmit Data Register
- TSR - Transmit Shift Register
- TXE - TDR Empty; IRQ - Interrupt Request
- volatile - C keyword that tells the compiler that a variable may be changed
- TXEIE - Transmit Interrupt Enable
- UART and USART - (refresher) Universal Asynchronous Receiver-Transmitter; Universal Synchronous/Asynchronous Receiver/Transmitter
To really understand the USART protocol, I'll need to experiment with it directly. Once I finish the chapter, I will look up USART tutorials specifically for STM32 products.
3/1/2023
Bare Metal C
I finished Chapter 10 today. I didn't care for the second half of the chapter like I did the first. I found it difficult to follow, not because the material was too complex, though it certainly is complex, but because several things were glossed over that I think should have been clarified more. That's okay. I like this book as a whole and I have no problem consulting other resources to fill in any gaps. Before I continue to Chapter 11, I'm going to explore UART, polling, and interrupts more thoroughly.
This article on the UART Protocol is an excellent distillation. Much of it was review for me, but it also gave me some new mind maps to use when thinking about UART. I really want to get a firm grasp on serial communication. Here are some steps I can take:
- Implement my own STM32 program that sends and receives packets via UART on the Nucleo MCU.
- Find a device with an embedded system and see if I can connect to it via UART and read its log data.
3/2/2023
Exploring the Job Market
I stayed up way too late last night combing the internet for practical examples of embedded systems being used in the field. I browsed job listings to get a sense of what I might be aiming for, and I went on Reddit to get people's personal accounts. I got a little discouraged; everyone was talking about how difficult it is to get started in embedded systems and to get into the field as a professional. To lift my spirits, I explored other realms of development I could get into. I stumbled upon this repository, and it got me thinking that I ought to start contributing to open source projects if I can. It would be practical way to hone my programming skills since I'd be working on real-world projects. Perhaps I can make this effort the primary way I practice C++.
I also watched a couple of Jacob Sorber's videos on embedded systems this morning, and I regained my enthusiasm for the subject. I know I need to keep pursuing embedded systems; I just need to adjust my current learning process. Yesterday, I said I would linger on UART for a while before proceeding to Chapter 11 in Bare Metal C. Now, I think I'll move on to Chapter 11 sooner than later and plan on returning to the topic of serial com, among other things, when I begin the STM32 class on Udemy.
C++20 Masterclass
Alright, I've decided to toss my completionist nonsense in the bin and start cherrypicking this course. There is way too much content for me to sit there and endlessly review concepts I already know. It isn't a good way to move forward. If I need to scratch that completionist itch later on, I can come back and cruise through the content I skipped in a casual manner. After I finish Section 14, Control Flow, I'm jumping to Section 18, References. It's time to make practical choices to get me out of this malaise.
3/3/2023
C++20 Masterclass
Having finished section 14 yesterday, I started on section 18, References. I am now committed to only completing sections that present new information to me. I'm tired of reviewing - it's burning me out and wasting my time.
3/4/2023
Bare Metal C
I started reading Chapter 11, which was on the Linker. It goes into great detail. I’ll likely need to read it more than once to fully grasp everything. The example program was the most helpful part:
/**
* A program to demonstrate various types of variable
* storage, so we can see what the linker does with them
*/
int uninitializedGlobal; // section bss
int initializedGlobal = 1; // section data
int initializedToZero = 0; // section BSS
// aString —- initialized variable (section bss)
// “A string.” —- constant (section text)
const char* aString = “A string.”; // String (pointing to read-only data)
static int uninitializedModule = 2; // section bss
static int initializedModule = 2; // section data
int main() {
int uninitializedLocal; // section stack
int initializedLocal = 1234; // section stack
static int uninitializedStatic; // section bss
static int initializedStatic = 5678; // section data
while (1)
continue;
}
This helped clarify the three main sections, text, data, and bss.
Podcasts
I started listening to Embedded FM podcast, and I have to say I really like it! I listened to episode 442, “I Do Like Musical Robots”. It was all about building hard and soft synths, midi controllers, and much more. I’ll keep listening!
Mastering MCU (Udemy Class)
I watched the first few lectures in this course to find out which MCU I needed to purchase for the course. Once I found it, I went ahead and bought it. I’ll finish Bare Metal C part II, and then I’ll get started for real with this course.
3/6/2023
Code: The Hidden Language of Computer Hardware and Software (book)
Finishing that slog of a chapter, 17, I was free today to enjoy reading Chapter 18, From Abaci to Chips. It provided a nice survey of the history of computing, as this book has already done many times. Here were my main takeaways from the chapter:
- “In the eighteenth century (and indeed up to the 1940s), a computer was a person who calculated numbers for hire.”
- The anecdote about the moth found in a relay in the Harvard Mark II computer and how it constituted the “first actual case of bug being found.”
- Von Neumann pioneered the concept of storing the program instructions along with the data in the computers memory. “These design decisions were such an important evolutionary step that today we speak of von Neumann architecture.” This architecture creates the “Von Neumann bottleneck,” where the CPU is now tasked with not only executing instructions but fetching them from memory beforehand. Reading about this bottleneck, I thought about Apples new chip, the M1, and I wondered if it is an example of overcoming the bottleneck. In my cursory investigation, I seem to have found that it does not eliminate it, but significantly “widens the neck,” so to speak.
- “It wasn’t until the mid-1950s that magnetic core memory was developed. Such memory consisted of large arrays of little magnetized metal rings strung together with wires.” Reading this in the book, I flashed on a video I watched months back demonstrating this very thing: Magnetic Core Memory
- The biggest takeaway was my newfound understanding of the term integrated circuit and what it really refers to, the concept of making circuitry with transistors, resistors, and other components all out of one piece of silicon.
After reading this chapter, I experimented once again with transistors, trying to get a better understanding of how they work. I read this article and put together this simple little circuit, using my multimeter to measure voltage drop across the collector, emitter, and base.

3/8/2023
Bare Metal C
Finished chapter 11, but I chose not to complete the problems at the end. I will return to these problems, or ones like them, when I’ve had a chance to practice the concepts more. I’ve gotten a lot out of this book, but these latest chapters have had too much of a “knowledge dump” format for me. I want to have more opportunities to apply things.
3/9/2023
Bare Metal C
Read through chapter 12, which was all about the preprocessor. This elucidating chapter reminded me of the value this book has added to my learning process. Key takeaways:
- The #ifndef and #endif directives that encapsulate the declarations in a header file are called sentinels.
- The preprocessor does not understand C syntax; macros are merely word replacement machines. Despite this limitation, they can be used for complex purposes, but it is generally best practice to use macros in this only way if there is no better alternative, as with ordinary C code.
- Parameterized Macros can spoof the behavior of functions. The STM32 library occasionally uses them in this way.
Student Log
I thought I was done with this one too, but I needed the edit_student() function so many times that I broke down and added it tonight. Next, I want to tidy up the codebase even further and to add a feature that allows the user to reinstate deleted students.
3/12/2023
Inventory Manager
Things come back sound don’t they. After the potential to deploy this application was revived, I set to work today making important updates to the design so that it can do everything it needs to do. My main focus for today was getting the items list in Django admin to be reorganizable. I was pleased to find that others had developed packages to solve this very issue, which would have been nontrivial for me to implement on my own. I found django-admin-ordering repo on GitHub. I was able to add it to my application and get it working; however, it doesn’t work with touch screens so far. I need to find out if I can add that, or if I need to choose another package like this one. There are several others on GitHub.
3/13/2023
Inventory Manager
After much toil, I was able to get my row-highlighting JavaScript function to work. The function itself was very simple: it only needed to highlight a given row in a table when a button in that row was pressed. I wrote the code, but it never seemed to do anything. Finally, this evening I opened the browsers inspect tool to find that the function was not even appearing in the JavaScript file, though previous functions I’d written were showing up. I immediately suspected that the cache was to blame: I cleared it and voila, my function started working.
3/14/2023
Inventory Manager
In my efforts to add a default message feature to the email boxes, I found redundancies in my finalize view. I was able to get everything working and make it look cleaner in the process! I believe I improved performance too. I believe I have added all the functionality that I needed to, and now I can begin learning how to deploy a Django App.
3/15/2023
Inventory Manager
Today was all about preparing my project for deployment.
- First I revisited the Django Deployment Checklist and found the very useful
python3 manage.py check --deploycommand, which scans the project for anything that needs adding or removing before deployment. - Next, I visited How to Harden the Security of Your Production Django Project, where I followed the tutorial in its entirety. I made some tweaks based on the needs of my project, but ultimately I was able to run the aforementioned command with no errors or warnings when I was done. The main change suggested by the article was to create two new python files, development.py and production.py, both of which inherit the base settings from base.py (settings.py renamed). With these two new files, I can easily indicate which mode I'd like to use by changing the
DJANGO_SETTINGS_MODULEvariable in my.envfile between'mysite.development.py'and'mysite.production.py'. - The next step is to explore server options. Currently, I'm looking at Railway.
3/16/2023
Inventory Manager
Explored the possibility of using Railway to deploy my Django web app, but I ran into several hiccups. I think my installation of NVM is faulty, and the railway login command throws an error, Unable to parse config file. It never logs me in. I tried uninstalling and reinstalling various packages to no avail. I’ll try again tomorrow.
3/19/2023
Inventory Manager
I’ve been on the verge of chucking my computer out a window the last few days! Deploying this Django app has proven to be a much more complex affair than I anticipated. It’s a classic case of expectations killing my morale. It would have been better for me to enter this stage of the project with an open mind. Starting a project and expecting it to be easy sets one up for pain and suffering.
First, I tried using Railway to deploy my app, but I kept running into problems with the Railway CLI App: NPM and Node.js weren’t working properly and nothing I tried fixed it. I then tried using the fly.io platform, and I don’t remember all the issues I faced, but I got so fed up that I finally consulted MDN Web Docs and found a tutorial that has walked me through all the deployment steps in great depth. So far, things are actually working, though I have had some hiccups along the way. With some more troubleshooting, I think I’ll finally be able to deploy this app on Railway.
Later today, I used GPT-4 to answer a few of my questions about deploying Django apps to Railway. Though it didn’t answer my main question, GPT-4 gave me a much clearer understanding of the purpose of many of the configuration files and variables that Railway requires. In other words, I gained a better sense of how things all fit together.
3/20/2023
Inventory Manager
Woohoo! I successfully deployed the app, and it is now reachable on the internet! The latest problem I was facing was embarrassingly simple: I hadn’t clicked “Generate Domain” in the settings panel on Railway. I found my error after consulting the Railway Discord server, which proved a great decision.
After I completed this step, I ran into some other small problems, which I was able to troubleshoot with the help of Discord once again. The SECURE_SSL_REDIRECT variable in my settings.py was causing the app to throw the “too many redirects” error. Moreover, I hadn’t added the project url to ALLOWED_HOSTS or CSRF_TRUSTED_ORIGINS. Once I made these changes, the app was visible online!
Now, I’m making a list of tweaks I need to make to the app. I’ve just now improved the CSV layout for non-emailed orders, and I made only non-zero values mandatory to confirm in the take-inventory template.
Learning Rust
I’m trying to let myself explore whatever is immediately interesting to me. I’ve been wanting to explore the Rust ecosystem for some time now - I understand that it has a thriving community, excellent libraries, and it’s safe and pragmatic compared to other high-performance languages like C++. I’m working through “The Rust Programming Language book” to get a solid grasp of the syntax, but then I’ll quickly shift into building projects. Perhaps I’ll build a website with rust and WASM!
Takeaways:
- ‘!’ as in
println!indicates a macro. - .toml stands for Tom’s Obvious Minimal Language
- Variables are immutable by default in rust, but
mutlet’s us make them mutable. I think this is akin to theconstkeyword in C/C++, yet it is the default. String::new()seems to instantiate a vector.new()is an associated function.- A “Result,” which is returned by functions, is an enumeration. Rust requires that “Results” be handled. In other words, Rust make error handling mandatory!
3/21/2023
Learning Rust
Here are today's key takeaways:
-
Rust uses "crates," which are essentially libraries, as in C/C++, Python, etc.I'm impressed by the level of organization of crates, with a dedicated webpage, a simple way to include them in a rust program (via appending them to a dependencies list in the
Cargo.tomlfile. -
The
Cargo.lockfile is a great innovation. It is created when you runcargo buildfor the first time, and it "locks" the current version of each dependency. That way, when those dependencies are updated, your program won't break:Cargo.lockwill ensure that your program continues to use the older versions until you choose to update on your own time, runningcargo update. -
The
matchkeyword seems to function much like a switch statement in C, yet thematchconstruct is certainly much more feature-rich and powerful than an ordinary switch statement. -
Rust includes something called "Shadowing," where a variable name can be reused. In other words, if we want to convert a char into an int in C, we have to do something like this:
// --snip-- char numChar = '5'; int num = (int)(numChar - '0'); // --snip--but in Rust we can do the following:
// --snip-- let mut num = String::new(); // user enters a value let num: u32 = guess.trim().parse("Please type a number!"); // --snip--
3/22/2023
Inventory Manager
I made it my task today to migrate the data from the sqlite3 database to PostgreSQL. It was an arduous process, but with the help of this video and this article, I got the job done. I started with the article to download PostgreSQL and learn how to serialize all the data in db.sqlite3 into a .json file. The video was perhaps the most illuminating, however. It explains how to start a PostgreSQL database in Railway itself. From there, it's simply a matter of accessing the DATABASE_URL variable generated by the database from the DATABASES dictionary in Django's settings.py. I used the dj_database_url method to do just that. Before I used the DATABASE_URL variable, I plugged in the actual url (without pushing to the repository, an important detail) so that I could run python3 manage.py loaddata data.json without the interpreter throwing a DATABASE_URL is undefined error. Once I successfully migrated the data to PostgreSQL, I replaced the literal url with the variable and pushed to the repository. That was all that was needed! I'm very close to finishing this project!
3/24/2023
Bare Metal C
I finally got around to doing the practice problems for the final chapter in Part I. There were all about practicing writing macros with the preprocessor. Here are two of the macros I wrote:
#define SWAP(a, b) \
a ^= b; \
b ^= a; \
a ^= b;
and
#define islower(x) \
(x >= 97 && x <= 122) ? 1 : 0
Having completed Part I, I will probably move on from this book. Part II is all about C for big metal, a topic I’ve had my fill of for a while (most of Part II would be review). Perhaps I’ll browse through it in the future, but for now it’s on to the new!
3/25/2023
Learning Rust
I bought an eBook today, Rust Web Development, published by Manning. I do really want to learn Rust as it seems like a language likely to be used more and more going forward. Moreover, it is very elegant and well-thought-out in its design. At first, I was tempted to fall into my old habits, buying a book that is a pure language guide, but I'm tired of the "ivory tower approach" to programming. I need to get books, courses, etc. that take me through a practical process. A friend of mine told me he might need my help building a website for a business he wants to create. This effort to learn Rust for web development (and ultimately more) could prove practical indeed if it allows me to build a highly-performant website for him.
Also, I completed Chapter 3 of the Rust Programming Language book. I intend to work my way through this book, but I will do so swiftly, skimming over any content that is merely review to me. Here's one of the main takeaways from Chapter 3:
- Expressions versus Statements. Expressions have return values that can be captured and assigned to variables while statements simply perform some action without returning any values. This distinction creates some interesting opportunities. For instance, in Rust, you can have a single variable capture the result of some multi-line code snippet inside a scope as long as the final line is an expression.
let y = {
let x = 3;
x + 1
}
This is valid Rust. The final line inside the scope is x + 1 and its lack of a semicolon makes it an expression, which has a return value.
3/26/2023
Learning Rust
I booted up my old Kindle today and loaded the “Rust Web Development” book on it. I read the introduction, and it served to stoke my interest in reading the book. I believe that when I’m completely done with the Inventory Manager App, I will embark on this Rust journey as well as the Embedded Systems course in Udemy. I’ll likely only access the C++ course when I really need it, in the midst of a C++ project for instance.
Anyhow, in the Rust Web Development Intro, the author stated the book is designed to pick up where chapter 6 of “The Rust Programming Language” left off. This clear benchmark served to reinvigorate my reading of the latter. Once I finish chapter 6, I’ll move on to the new book on my Kindle.
The Rust Programming Language Chapter 4, Ownership - Key Takeaways:
- Ownership eliminates the risk of a double free.
- A dynamically-allocated variable may have only one “owner” at a time. If a
Stringvariable is assigned to anotherStringvariable, then the first is no longer valid and can no longer be referenced: it transferred ownership of the value. If the programmer explicitly calls theclonemethod on the string, then the value will indeed be fully copied on the heap and bothStringvariables will be valid. This concept is in keeping with Rust’s safety philosophy. I’m seeing a trend: anything that is considered risky in programming must be explicitly executed in Rust, and anything that is considered the safest, standard way of doing things is what Rust does be default. Other languages such as C do not operate in this manner. - Functions take ownership of a variable when it is passed as an argument. They can then return the variable and transfer ownership back outside the function. In some cases, this procedure can be impractical; this is where the benefits of references come in.
3/28/2023
Learning Rust
I completed chapter 4 of The Rust Programming Language and here are my key takeaways:
-
With the definition of Ownership above, the concept of borrowing using references makes sense. For example, references allow us to pass a variable to a function without that variable losing ownership. Instead, the reference will go out of scope at the end of the function and the borrow will be eliminated. This is useful in situations where you don't need the ownership to change multiple times over the course of a function call.
-
You cannot have two mutable references borrowing the same variable at the same time, but you can have any number of immutable references.
-
"A string slice is a reference to part of a
String."let s = String::from("hello world"); let hello = &s[0..5]; let world = &s[6..11];
3/29/2023
Inventory Manager
I worked on several different issues for this project today. Here’s a list:
- Changed the color of the rows in my createPDF() function.
- Debugged the 500 error that occurred when trying to access analytics for an item with no order history. It was merely an error in the spelling of the HttpResponseRedirect link.
- Replaced django-admin-ordering package with Django Admin Sortable 2, and it has much better functionality for my purposes.
- Found an IntegrityError in my model setup. When a user tries to delete an item that has an order history, a 500 error is thrown. I fixed this by changing the
on\_deleteto SET_NULL and by addingnull=True. The 500 error is gone, but now when an item is deleted, and references to it in order history are also deleted. This is because of the ForeignKey in the Order object is used to fetch the item name from the corresponding Item object. I’ll need to change this.
3/30/2023
Inventory Manager
My main goal for today was to fix the issue of the deletion of inventory items altering order history: I wanted the order history to persist unaltered even if inventory items were deleted. With some trial and error, I was able to solve this issue by adding a brand and unit field to the Order model itself. That way, the Order table doesn't need to perform a reverse lookup on the item ForeignKey just to get those data. I will perhaps see if the ForeignKey is even necessary in the Order table anymore, but that's a pursuit for another day.
3/31/2023
Learning Rust
Takeaways from chapter 5:
- Structs in Rust are rather similar to structs in C.
- A function can be used to instantiate a struct.
- Rust allows us to create tuple structs, which is sort of like type-defining a tuple so that it cannot be interchanged with another tuple with the same quantity and types. A good example is in the case of setting parameters for functions. You can use a tuple struct to make sure a function only accepts tuples of a specific name. I suppose it’s almost like namespacing a tuple to a particular use case.
- We can define a set of functions inside an
implblock to associate them with a given struct. Functions defined in this way are called associated functions, of which methods are a subset. Using theselfalias as a parameter in an associated function makes it into a method and therefore callable via door operator. Otherwise, associated functions that aren’t methods are effectively namespaced to the given struct and they are called via the::operator. A common use case for a non-method associated function is in creating a new instance of a struct, essentially like a constructor.
4/7/2023
I think I needed a break. I found myself stalling out again. I'm nearly done with this inventory manager application, and then it will be on to the next thing. I'm greatly intrigued by the Rust language, but unless it can furnish we will actual work and projects to build, I won't spend my time on it. I'm acutely aware now that my completionist mindset has most always been an obstacle to me. If something is not sparking my interest or helping me to gain more tangible experience in the real world, then I don't want to waste my time on it. Hence, I gave up on the C++20 Masterclass on Udemy; it was too much of a pure language course, and I need more opportunities to build and create useful things. I also gave up on the Data Structures and Algorithms course. I must say that is a topic I need to explore further, but there's got to be a way to do it in the context of projects! I also have the Embedded Systems course on Udemy, and it still greatly intrigues me, but I'm pained to say that I'm prepared to give it up as well if it hinders me. I'm learning to listen to that stuck feeling that lodges itself inside me when I know I'm spinning my wheels.
Inventory Manager
Today I knocked out several tasks that were nagging at me:
- Verify that the Sortable Admin plugin will perform how I want it to.
- Add filtering capability to ItemAdmin so the user can display only shed or only shop items. Once filtered, the user can then reorganize with the Sortable Admin feature.
- Remove widgets from the Supplier field in the add item form.
- Make default_message not required in the Supplier form.
I'm very close to finishing this since it is already deployed. I simply need to repopulate the inventory list and monitor the way the apps interface behaves as I do it.
Rust Web Development
I skimmed over chapter 6 of The Rust Programming Language: my new book, Rust Web Development, says that's as far as I need to read in order to begin using the language in a project. I've moved on to the new book, and I'm committed to seeing what I can learn from it. If it begins to feel like a deadend for me, I will examine the sentiment and oust the book if the feeling persists. I must be ruthless!
Chapter 1 in Rust Web Development was all about introducing Rust and how it can perform as a language for web development though it is primarily a language for systems programming. Rust is increasingly used in a variety of sectors as many find it to be quite easy to use once you get the hang of it. In addition, as I've heard several times before, it is very safe. Reading through the first six chapters of The Rust Programming Language, I was struck by the first that Rust simply reverses a lot of the standards of other less-safe languages. For instance, variables are const (although Rust calls it immutable) by default and the programmer must explicitly declare it otherwise `let mut some_var = 6;' in order to change it. It's a simple and ingenious reversal, and it's only one such example. Much of what chapter 1 in Rust Web Development had to say was a little over my head, but that's ok since it was merely meant to be an introduction. Moreover, the author himself said "you don't need to understand this yet" several times.
Exploring Other Possibilities
It remains to be seen what will become of my Embedded Systems endeavors. I will continue to explore Rust Web Development, and I finally arrived at the notion that I should study Artificial Intelligence more deliberately. I intend to take Harvard EdX's CS50AI class at the earliest convenience. It feels like the right call. However, you can imagine my concern about possibly leaving Rust and Embedded Systems behind for now. I don't know how I'll do all three; it's likely I could pick two, but I don't which yet. Nevertheless, taking CS50AI seems like the absolute right decision.
4/10/2023
CS50AI
Woohoo! I'm beyond excited to be enrolled in another class offered by Harvard EdX! Today, I watched the whole two-hour introductory lecture, and I can tell immediately that I'm going to both like this course and be challenged by it. Right away I was fascinated by the practical use of Data Structures and Algorithms. The introduction made it clear just how essential they are to the developemtn of Artificial Intelligence, which is not a surprise. This is all a breath of fresh air since my experience with DSA has thusfar been mostly theoretical or isolated to impractical demonstrations. I certainly gained a good understanding of many of them and even employed a few in my own projects, but I still felt I was missing a practical understanding in general. Anyway, I'm excited for this course!
Edit from 6/5/2023: I was direct toward this course after reading an article called 7 Best Artificial Intelligence (AI) Courses for 2023. I have kept this article open in a pinned tab for the past two months. It recommends other courses that I will likely pursue once I'm done with CS50AI.
Rust Web Development
I read Chapter Two up to 2.1.5. It's a quick review of the Rust ecosystem and syntax, and I find I'm able to follow it quite easily. Reading this part of the chapter, I got a better sense of the purpose of the Option<> type. It's simply another example of Rust's reversal of the standard programming modus operandi. Variables cannot be empty unless the programmer explicitly declares that they can be so, and that's what the Option type accomplishes.
4/11/2023
Rust Web Development
I read more of Chapter Two and I came away with a few questions:
- What is a runtime in web programming?
- What is a kernel API?
- What is Rust's Future type?
4/12/2023
CS50AI
I completed the Degrees project today. It took some doing and I had to push myself to get it done, but I really enjoyed it. I’m eager to continue in this course, getting a better grasp on AI and on Python. The notes I’ve taken for this course can be found here.
Here’s the notes most pertinent to the project I just completed:

4/13/2023
CS50AI
I didn’t start the next project today, but I did challenge myself to submit the degrees.py project via git instead of submit50. It was more of a hassle than I anticipated, but in the end I got it. Before submitting, I tested the function I’d written once more and I found that there was an error. When an target did not exist in the stars.csv file, the program would spin endlessly, expanding the same nodes in a loop. I realized I’d forgotten to include an additional explored data structure to keep track of those nodes that were found to not contain the target. This solved the problem.
4/15/2023
Inventory Manager
Worked with the client to put the finishing touches on everything. We got the web app set up with their email account, all the correct contact info was added, and I made last minute changes to the app itself.
I changed the emailing process: now when an order is sent, the current user and the host user both receive a copy of the email. This was requested by the client for their own reasons, but it also solved the problem of having no backup for orders that are not sent to a supplier email.
I deleted the inventory\_order table in the Postgres database in order to clear all the spoof testing orders, and of course this caused a problem for the app. I expected it to be an easy fix, a matter of running python3 manage.py makemigrations to recreate the missing table. However, I had to go in and manually adjust the migration files so that there was no former record of the order table. That way, Django would see it needed to actually create the table again.
Everything should be working now - the app will get its first official use in a couple day!
4/16/2023
CS50AI
I started and completed the Tic Tac Toe project today. The instructors more or less wrote the whole game, but they left the students to complete a series of functions in a separate module that was imported into the main source file. The first several functions weren’t terribly difficult to write. Mainly, they gave me a chance to become even more familiar with Python syntax.
The final function, minimax proved to be more of a challenge. I had a moderate understanding of the concept to start and I had copious notes from the lecture. Using those notes, I cobbled together a working function, writing two helper functions, max_value’ and min_value’ in the process. Once again, I derived my understanding from the notes I took. The program worked the first time I tested it! What a great feeling.
The project specifications stated that it was optional to implement Alpha-Beta Pruning as an optimization. Wanting to get as much as I can from this course, I decided to try it. At first, I tried to reason my way through the concept alone. By my estimation, I got awfully close, but there was a vague sense that I was missing something, so I decided to go online and learn more about Alpha-Beta Pruning. I watched several videos, but Minimax With Alpha Beta Pruning and Alpha Beta Pruning / Cuts were the most helpful. I took notes from both videos, and ultimately they gave me the understanding I needed to implement it.


4/17/2023
Inventory Manager
I spent many hours today making significant modifications to the app. We had a trial run of the app at the coffee shop, and there were a handful of things that went wrong. The first thing to fix was the inability to move seamlessly between the take_inventory and finalize templates, so I reworked the take_inventory view to allow for this. Now the user can push a back button and easily go back from finalize to take_inventory, and they will see the most recent changes they made. I have more to work on, but I hope it won’t take me too long. I’m ready for this project to be wrapped up so I can fully move on to greater things.
4/23/2023
Inventory Manager
The past week, I have toiled over this app. I have a list of features I need to implement based on what went wrong on Monday, and I've checked off the ones I've completed:
- Add back button to finalize template (Change the way take_inventory and finalize views interface) [x]
- Add orders preview to finalize [x]
- Create spacing between categories []
- Add different colors for seasonal items (orange for Fall and blue for Winter) []
- Make default_message dialog box larger []
I'm very ready to be done with this project and move on to more interesting pursuits.
OpenAI ChatGPT API
Today for the first time I created an API key in my OpenAI profile and began configuring my development environment for the openai module. I'm excited to try building applications with this technology! I found a quick start guide in the documentation section on OpenAI's website, and I plan to sit down and read through it carefully. Perhaps I can use their technology to build a custom app for music teaching!
4/24/2023
Inventory Manager
I’m happy with the progress I made today. Here’s a list:
- Finish the preview feature in finalize. [x]
- Make default_message dialog box larger (I replaced CharField with TextField in the model). [x]
- Correct the ordering of items in Order in Order History, which was caused by the my_order field. [x]
- Add seasonal option to items with color-coding. []
- Create spacing between categories. []
CS50AI
I started Lecture 1 today, which is on knowledge. I can tell I’m going to love this course and the subject matter; I already do. It is bringing together so many things I’ve already been interested in: language and its structures, Philosophy (specifically Philosophy of Mind), Propositional and Predicate Logic, and much more. I feel uniquely prepared to dive into the field of AI. It’s unclear whether I will be able to make it professionally, but I am interested in this field regardless.
4/25/2023
AI Education
Started the day with a series of YouTube videos on AI. My favorite by far was on the research conducted by CETI, Cetacean Translation Initiative, which is trying to use machine learning and AI to communicate with sperm whales. Here is the video. I plan to learn more about it, but I was already impressed by the statistical language models they were using to give an AI the ability to match two different languages one-to-one. In other words, both languages are subjected to the same statistical model, which maps out the language and assigns weights to each word based on the frequency of usage and other factors and then compared the results from both. Apparently, it has been able to successfully align the languages and allow tranlation to occur. CETI is hoping to do this very same thing with sperm whales, aligning a human language, say English, with the clicking language organized into codas of sperm whales.
CS50AI
I finished the lecture today. It was packed with content! I processed the information all day today. Taking quiz 1, I was stumped by the question on entailment. It was unclear how the term was being used: did it mean that sentence A necessitates sentence B or that sentence A allows for sentence B? All my investigation suggested the former, but I couldn’t find an answer among the multiple choices that demonstrated that necessity. I’m still trying to sort it out currently. You can find my notes to lecture 1 here.
4/26/2023
CS50AI
Today, I practiced with Entailment. I used ChatGPT to generate a list of practice problems, and working through a few, I got a much clearer understanding. There was an amusing exchange between GPT and me. It can be found here. I also drafted an analysis of this conversation, which I added to files in this repo - here.
4/28/2023
CS50AI
Worked on the Knights project and almost completed it. It is based on the logic game Knights and Knaves, which I’d like to play more on my own too.
Research
I searched Google for the most advanced AI systems currently available, and I started reading about AlphaGo and AlphaGo Zero, two highly-advanced ANI systems, the first of which successfully beat the Go world champion. Later, the latter beat the former at Go, learning the game from scratch using a a new form of reinforcement learning that effectively allows the system to teach itself by playing games against itself. I downloaded an article from the Deepmind website (Deepmind is owned by Google), and I plan to read through it once I have the time! I want to stay up to date on these things.
4/30/2023
CS50AI
Yesterday and today, I worked hard on the Knights project. Several times I successfully solved the puzzle, but I was unhappy with my solution because it either didn’t reflect the structure of the logical sentences well enough or too much of my own reasoning was involved. Every time I tried to model the logical sentences closely to the text of the problems, I would not get the right answer. Reading the problem specifications again, I found that I wasn’t adding the inverse of each logical sentence to the knowledge base. For example, I was writing the following:
Implication(AKnight, And(BKnight, CKnight)),
but I wasn’t also writing this,
Implication(AKnave, Not(And(BKnight, CKnight)),
Once I added the I inverse for each sentence, my knowledge bases performed correctly!
5/2/2023
CS50AI
I’ve been working hard on the Minesweeper project, and today I nearly got it. There’s several flaws in my add_knowledge function that need working out, but I couldn’t wrestle with them today. Tomorrow I’ll try again; I think I’ll study the whole program thoroughly and take notes to make sure I understand everything completely. I think that will clarify the problems for me.
OpenAI ChatGPT Release Article
I read through the article announcing the release of ChatGPT on Nov. 30, 2022. I hope by reading things like this frequently to help induct myself into this space. I want to know my way around the AI landscape. There are several other great articles on OpenAI’s website that I plan to read.
5/7/2023
CS50AI
Still working on the Minesweeper project, and I’ve been banging my head against a wall. It’s a process of 3 steps forward, 2 steps back. Yesterday, I believe I made some crucial progress. I sat down to code, and I quickly noticed errors in my logic that I hadn’t seen before, likely due to fatigue. Throughout this learning process, I’m getting a much better understanding of what is means to program an agent and its environment. I’m determined to conquer this project!
Research
As usual, I’m watching numerous videos and reading many articles everyday to get my mind wrapped around ML, AI, deep learning, etc. Here’s a couple videos I enjoyed:
- Google AI Documents Leak “We Have No Moat, And Neither Does OpenAI
- AI ‘godfather’ quits Google over dangers of artificial intelligence - BBC News
Minds, Brains, Science by John Searle
A few days ago, I read the first chapter of this book, which I bought on a whim from Half Price Books several years ago — likely in 2019, when I was reading Heidegger’s Being and Time. Today, I read chapter two, entitled Can Computers Think? This is the chapter that presents the Chinese Room thought experiment. It’s clear that the substance of Searle’s argument is in his categorical distinction between Syntax and Semantics. His argumentation makes sense, but I doubted the strength of the aforementioned distinction. I’m eager to read more!
5/8/2023
CS50AI
After much toil, I finished the Minesweeper project. I’m reminded how important it is to step away from difficult problems so that one’s head can be cleared. Returning to this project today, I could clearly see what I was doing wrong. I can’t describe the feeling of relief and accomplishment that came over me when my AI beat the game for the first time. I’ve added my notes to the project folder.
Making Plans
I made a list of resources, platforms, and apps to check out. Here’s the list:
What to Explore:
- ChatGPT Plus
- Slack, for CS50x and CS50AI
- Telegram
- Steamship Hackathons
- Podcasts: Practical AI, Talking Machines, Eye on AI, Linear Digressions, Voices in AI
Fronts:
- Understanding the Science, the research of AI
- Understanding philosophy and implications
- Building projects, using AI tooling
5/9/2023
CS50AI
I watched almost half of lecture 2, which is on Uncertainty. I’m glad I took a break — I definitely need to review my notes before continuing.
OpenAI
I upgraded to ChatGPT Plus today, and I’m very excited to explore it and see how it compares with GPT-3.5!
5/10/2023
CS50AI
I’m having a hard time getting through this lecture in one sitting due to this week’s business! Today I watched another 30 minutes or so, and I’ll once again have to review my notes for everything. I think I’m getting the hang of things, but this lecture still feels filled to the brim with content. In fact, each lecture has felt like an enormous crash course in its respective topic. It’s giving me a good idea of the almost limitless breadth of the field of Artificial Intelligence.
Journal Article from JAIR
I’m really excited that GPT-4 found this website for me! It’s a database of free research articles for AI. I’ve already read one article, which I added to this repo. It’s called Viewpoint: Artificial Intelligence Accidents Waiting to Happen?. It was a quick and easy read, but I found the concept of normal accidents fascinating. A researcher named Perrow, who wrote the book entitled Normal Accidents, theorized that in any system that is both complex and has tightly-coupled components, it is only a matter of time before an accident occurs. These normal accidents are comprised of small errors that are innocuous on their own coming into alignment with one another and causing a catastrophic failure. Given enough time, it becomes probable that these small errors will eventually align.
The best example with respect to AI is the idea that has been floated to couple LLMs with Autonomous Vehicles to allow the user to interface with the vehicle using verbal communication. With the current state of such technologies, such a coupling could very easily result in a normal accident.
5/12/2023
CS50AI
I finally finished the Uncertainty lecture this morning. In all the Harvard EdX lectures I’ve watched, this one by far presented the greatest amount of concepts in 2 hours. My head was absolutely spinning after finishing it, yet my curiosity is absolutely piqued. I intend to explore Bayesian Networks and Markov Models more thoroughly on my own by way of YouTube videos, research articles, and exercises.
OpenAI Whisper API
Finally, I found some time to start experimenting with OpenAI’s APIs, specifically their open-source speech-to-text, Whisper. It’s really cool. I read the readme.md and built the first example program with a few tweaks and voila! It feels like cheating because I’m outsourcing basically all the effort to the Whisper API. Anyhow, I’m excited to play with it more and perhaps start to see what makes it tick. I have plans to use it for my audio musings.
So often I’ve had thoughts I want to write down while driving. It’s the driving itself that elicits the state of mind for such thoughts. I’ve begun recording voice memos to capture my thought processes as I have them. From there, I want to use OpenAIs tools to turn the audio into a text file that I can easily edit, polish, and reduce down to a concise package.
5/13/2023
OpenAI Whisper API
Using the simple little program I wrote, I got transcripts of several of my voice memos! However, I was unhappy with simply creating another CLI app; I really want to make something that has a GUI and a little more polish to it, so I started exploring the tkinter Python library. It has the same feel and functionality as other GUI libraries I’ve experimented with. In the past, I’ve found writing GUIs tedious, but I’m determined to understand it better this time! I didn’t quite get it all working today, but I’ll try tomorrow.
5/14/2023
OpenAI Whisper API
I continued reworking my simple Whisper wrapper program with tkinter, and I found that my program was quickly devolving into the One Big Mess design pattern, so I hoped on GPT-4 and asked it, ”What is a standard design pattern using tkinter and Python?” It answered that the MVC Pattern (Model-View-Controller) pattern is a good choice. The Model holds the data and rules of the application, the View presents the GUI for user input and interaction, and the Controller is the liaison between the two, updating the Model based on changes in the View and vice versa. I began redesigning my program with all this in mind and I found that it all makes a lot of sense! I’m still trying to make sense of it all, so when I was done programming today, I pushed my work to a new experimental branch.
5/15/2023
OpenAI Whisper API
Working on this simple little program has given me a much better sense of Object-Oriented Programming in Python. I’ve learned about the super() method, which allows me to instantiate a class inside its own declaration (I think that’s what it does!); I got a better sense of Python’s double underscore variable (dunder); and I learned about the customtkinter library built on top of tkinter, which makes modern GUI aesthetic easier to achieve.
ChatGPT iOS Shortcut
I got a fun idea to create an iPhone shortcut that takes speech input, turns it into text and then passes that text into ChatGPT’s prompt field, and finally scrapes the webpage for the response. My first task was to write the JavaScript that will inject the prompt into the webpage at the correct HTML element. I accomplished this by using the inspect feature in Chrome to have a look at the webpages source code. Digging through the HTML, I found the element that encapsulated the prompt field. Then I wrote this JavaScript to manipulate it:
textInput = document.getElementsByTagName(“textarea”)[0]
textInput.value = “<Prompt variable>”;
button = document.getElementsByClassName(“absolute p-1”)[0];
button.removeAttribute(“disabled”);
button.click();
completion();
This is as far as I got today, but I’m quite happy with it!
5/16/2023
ChatGPT iOS Shortcut
After some trial and error today, I got the whole thing working! Here’s the entire thing:

I need to tweak it a little bit still; if ChatGPT’s response consists of more than one paragraph, the JavaScript in the shortcut only scrapes the final one. Evidently, each paragraph is contained in its own HTML element. I imagine it won’t be too difficult of a fix.
Later today, I went into the shortcuts JavaScript and added a for loop that iterate over all the paragraph tags in the given element, concatenating them. The script avoids any previous responses by added a “marked” class to any paragraph tags that have been previously accessed. Of course, this solution fails if the user refreshes the page because the HTML source code is fetched anew from the server. Even with that caveat in mind, my little shortcut is actually very helpful, and I’ll probably use it quite a bit!
5/17/2023
CS50AI
I discovered that CS50AI makes well-formatted lecture notes available for each section! I went through the notes to Lecture 2 today and really took my time. I wanted to get a better understanding of Conditional, Unconditional, and Joint Probability, Bayesian Networks, Marginalization, and more. I still have more to review, namely Markov Models. I’m determined to get a solid start on these topics even if I don’t go any deeper.
5/18/2023
CS50AI
During my breaks at work, I used GPT-4 to generate probability practice problems, and when I couldn’t quite figure out the steps to solve one of them, I had GPT-4 give me some help. The whole process helped me gain a much better understanding of the subject matter!
Finally, I tackled Quiz 2. Reading the lecture notes yesterday and doing the practice problems today made the quiz a breeze. I was able to think though each question, and I gave all the correct answers!
5/20/2023
YouTube Video on AI
A few weeks ago, I discovered a new YouTube channel, Wes Roth, that discusses the technical developments of Artificial Intelligence in a succinct format. I enjoy the way he presents information, as he often will make a video around an academic paper and explain its fine points. Here’s the link to the video.
In the description, he links to the paper he referenced, which I intend to read myself as soon as I can!
5/21/2023
Academic Papers
I started my reading with the article presented in yesterdays YouTube video, Tree of Thoughts, and this led me to another paper, Chain of Thought Prompting, the methodology of which is the predecessor of tree of thoughts. Finally, to conclude this small rabbit hole, I visited OpenAIs website to see what was new, and I saw the announcement that an iOS app for ChatGPT was released in the AppStore three days ago! The shortcut I made was just a temporary solution anyway. 😆
One last note, I tried to access the repository for the Tree of Thoughts demonstration, but the code was pulled recently to be cleaned, so I have to wait a little bit to see it and try it out.
5/22/2023
CS50AI
I worked on the first project for this section, PageRank, where we are implementing a PageRank algorithm much like the sort that Google uses to arrange its search results. Of course, the one in this class is probably much simpler.
The first task was to write the code for the transition model, which operates on the current state and generates a table of probabilities for potential future states; then the model pseudorandomly select one of those states according to the probabilities.
For the sample_pagerank function, As the model processes each state, we keep track of how many times the given state was reached as we iterate through the graph as many times as the sample number specifies. Then we generate the probability for each state by dividing the number of times the model selected it by the sample number.
The last thing to implement is the iterative_pagerank function, which uses a different method to arrive at similar results.
5/24/2023
CS50AI
It’s experiences like today that remind me why I love doing this. I sat down to write the iterate_pagerank() function and somehow the answers just came to me. I knew exactly how I wanted to write it within minutes! Here was my reasoning:
The function needed to calculate a given pages PageRank by adding the probability of selecting 1 page out of the corpus, adjusted by the damping factor, to the summation of the PageRanks of every page that links to the given page divided by that number of links. Here’s the equation:
PR(p) = (1 - d) / N + (d * summation(PR(I) / NumLinks(I))
In order to easily access a list of pages that link to a given page, I decided to invert the corpus and copy that into a new dict like this:
# Initialize all pages to equal probability.
for key, value in corpus. items() :
result[key] = 1 / corpus_length
# Invert the corpus, showing for
# the given page what pages link to it.
for page in value:
if not page in inv_corpus:
inv_corpus[page] = list()
inv_corpus[page].append (key)
In short, I was pleased with how quickly I arrived at this solution, and implementing it was a rush! I know it’s simple, but I’m proud of it nonetheless!
Job Exploration
I decided to explore other LLM development besides that of OpenAI and Google. I found an open-source community-driven effort called Hugging Face, and I made an account. I’ll need to explore it properly soon. I also found a platform called Cohere, which seems to be developing LLMs and APIs with which to use them. I found this company particularly interesting, and after looking at its available jobs, I’m inspired to try to push further into this space. Perhaps I can get a job at a place like Cohere!
Ideas
I got a wild idea to create my own personal AI model to train on my journals! I’m thinking it’ll be a good chance to get familiar with the likes of Tensorflow or PyTorch, and the project should be pretty meaningful to me. Once the model is trained on my journals, I hope to be able to chat with it and have it extrapolate on my own way of thinking! Perhaps I’ll learn new things about myself.
5/25/2023
CS50AI
I tested out both functions this morning, sample_pagerank() and iterate_pagerank(), and I encountered some problems when I ran them on the 2nd corpus. The main issue was that the two functions were not matching up in their results as they should. Moreover, the iterate_pagerank() function was running a negative value for one of the probabilities. I want quite able to solve the problem, but I’ll try again tomorrow.
5/29/2023
CS50AI
It took me the rest of the week to solve this one. It’s hard when my attention is divided between this and my regular job; some days I have more time than others and on busy days problems like this one seem more intractable! Nonetheless, I solved it using a few different strategies.
First, I reread the specifications of the problem and found I had overlooked the requirement of taking a page that either has no links or only links to itself and making it link to every page in the corpus; second, I got clear on what each variable needed to be and made their names as clear as possible; finally, to troubleshoot the function I was struggling with, I wrote several iterations across different files that I could import into the source file to see what worked.
5/30/2023
CS50AI
I spent all my study time trying to wrap my head around the Heredity project specifications! It’s a little difficult to grasp at first, but I started to get a handle on it. I’m having to refresh myself on the notes from the lecture for this one. I reviewed Marginalization, Bayesian Networks, Joint Probability, and etc. I didn’t get to writing code yet today. I admit that I’m a little clueless about how to begin! I’ll figure it out.
5/31/2023
CS50AI
Wow, this project is difficult to grasp, yet I’ve made progress. I was able to get all my functions written this morning, yet some parts of my output are still incorrect. I simply need to troubleshoot the conditional probability code snippet, where the probably of a child receiving the mutated gene is calculated with respect to the number of copies that each parent possesses.
Working on the normalize function, I discovered the error I had made on the PageRank project (for which I received a non-passing grade today!). I needed to find the total of all the probabilities and then divide each by that total. Once I finish Heredity, I’ll go back and fix the normalization in PageRank and resubmit it.
6/1/2023
CS50AI
Let’s get this month off to a strong start! I submitted heredity.py and I resubmitted pagerank.py. If they both receive a passing grade, I’ll be done with the Uncertainty module! If one or both do not pass, I’ll steel myself and try again. Here’s the corrections I made:
pagerank.py
- I was normalizing the probabilities improperly, making it more complicated than it was. I only needed to add up all the probabilities in the distribution and divide each probability by this sum. I refactored the code in each algorithm and turned it into a separate
normalize()function that I then used in both. - Initially, I had the while loop exit condition set like this:
difference = abs(current_pagerank - new_pagerank)
if difference > 0.001:
keep_going = True
- The problem was this did not account for rounding down. The difference that was calculated could be .00014, which would trigger the Boolean expression. What I needed to do was round the difference (here’s what I actually did, which I’m just now realizing might be incorrect!):
difference = abs(current_pagerank - new_pagerank)
if difference >= 0.002:
keep_going = True
- Perhaps I should have done this:
difference = round(abs(current_pagerank - new_pagerank), ndigits=4)
if difference > 0.001:
keep_going = True
heredity.py
- I kept getting the wrong values when calculating the child’s probability of inheriting the mutated gene. I thought the issue was with how I calculated the joint probability, but as I combed though it, I kept failing to find an issue. It finally occurred to me it was the
update()function all along. I simply needed to have each new probability be summed to each previous probability (+=) - I was simply reassigning the variable each time.
6/2/2023
TensorFlow
I started exploring TensorFlows webpage and YouTube tutorials today. I’m eager to start building stuff with this library, but I admit I’m daunted by all the things there are to learn! As I stated on May 24th, I want to build a model and train it on all my writings. In the end, I envision communicating with a Chatbot that remixes my own ideas and communicates them back to me. This might be an ambitious goal given my current knowledge, but it’s also a goal I’m excited about, and that’s important.
HuggingGPT
Over a week ago, I stumbled on Hugging Face, an open source AI/ML community. It seems to be the place to be if you’re trying to generate your own ideas and projects without the support of a company (I suppose it’s a good place to be regardless!). Anyway, I discovered a project called HuggingGPT, which seeks to employ GPT-4 as a sort of brain that interfaces with several more specialized models that were developed on Hugging Face. Ultimately, this extends the capabilities of every model involved, allowing them to coordinate their efforts and produce a complex and nuanced output.
I finally got around to reading the academic paper for HuggingGPT today, and I’m excited to try it out! This seems to be similar to the now-available plugins for GPT-4. However, I can see that what HuggingGPT offers is more extensive. Ultimately, I need to use it so I can draw my own conclusions.
6/4/2023
TensorFlow
I'm intrigued by Google Colaboratory and Jupyter Notebooks. The latter, I've seen crop up numerous times in my computer science exploration, but I've never gotten a good sense of how they work. Exploring the TensorFlow tutorials, I'm getting a better sense of them: Jupyter notebooks are essentially markdown documents with enhanced capabilities such as the ability to write and execute code snippets inside the document. Google Colaboratory is a cloud-based platform that hosts these Jupyter Notebooks and allocates some computing resources for each. It all connects to my affinity for organization! I'm eager to see how I can start using them.
In exploring TensorFlow, I've realized I dont' have a fundamental grasp of tensors themselves, so today I watched several videos to get started. Here's what I watched:
- What's a Tensor? - Dan Fleisch
- Multi-Dimensional Data (as used in Tensors) - Computerphile
- Tensors for Neural Networks, Clearly Explained!!!
Watching the first video gave me a much more intuitive sense of the vector as it appears in mathematics and it also made it much clearer how the term vector is used differently between math and computer science. As I watched this video, I began to see it - tensors probably have a different definition in computer science than in mathematics too. Next, I looked for a video on YouTube that would explain tensors in this way. Enter Computerphile.
The second video really distilled things for me. I began to get that feeling of intuition as I watched; this is the feeling I watch for when learning something new because it indicates I have gotten a foothold on the subject matter. I'll likely rewatch it to get an even better sense. Moreover, I will probably try to design a simple tensor in C or Python, not for use in a serious program, but for the purpose of understanding it as a data structure.
Finally, the third video confirmed my instincts. It made a clear distinction between the tensor of mathematics and that of computer science. Furthermore, it unpacked important terms of art such as TPU, which stands for Tensor Processing Unit. It is piece of hardware like a GPU or CPU that is specialized for processing tensors. Ultimately, the whole point of a tensor is to make large volumes of interconnected data much faster to index, which is generally the aim of any given data structure: he difference is the application. As the third video explained, tensors are preeminent in the building of Neural Networks, which not only need the efficient lookup that tensors provide, but also the ease of calculation. This last point I don't yet understand fully, but something about tensors makes them especially suitable for perform complex calculations, like that of altering weight and biases in backpropagation. I was excited to see that this YouTube channel had a host of other videos that all connect to this same topic. It has videos on backpropagation, neural networks, etc.
Inventory Manager
Out of nowhere, I started working on this project again. I discovered I have renewed energy to finish it since I let it sit for a while. Furthermore, I was able to develop a workflow using only my iPhone and Working Copy, a git client for iOS. I handled the NaN error in the take_inventory template, and I made it so the user cannot confirm a quantity and therefore proceed to the next page unless it is zero or a positive integer. Additionally, I altered the take_inventory view to split the item list into shop_item_list and shed_item_list, which was my original design. I removed it when I was working on the back button for the finalize template. Now, I was able to add it back in without compromising the previous work I did.
There's only a few things left to do:
- Make the take_inventory template display items with spacing every
nitems for legibility. - Add seasonal item color coding (I'll need to edit the model itself for this)
6/5/2023
Replit
I decided to take another look at Replit. I'm becoming more and more keen on making my workflow as portable and barrier-free as possible. It seems Replit will allow me to do just that. Their iOS app is quite nice, and I could see myself programming more often on my phone, especially if I had a portable bluetooth keyboard to go with it. As I poked around Replit, I discovered the learn tab. In it was a tutorial called Unlock the Power of LLMs like GPT with Python. I completed the first day of this tutorial. So far it is mainly a copy-paste tutorial, a thing I've avoided in the past. However, I'm trying to get some sort of foothold in the world of AI development, and this seems a reasonable place to start. I may end up subscribing to Replit if I find that it greatly enhances my workflow and learning capacity.
Research
I'm in the mood to explore my options for the future. I was looking at job listings on Indeed, and I noticed that most Software Engineering positions are requiring degrees I don't have and numerous years of experience. I've noticed this many times before, but of course with all the upheaval and layoffs that have occurred in the technology sector this year, the market has shifted toward employers - it is their market now and they have their pick of the litter. They can afford to demand the most excellent, highly-credentialed technology workers out there.
For my next search, I typed in Software Engineering Internship. I was pleasantly surprised by the number of listings with pay ranges from around $60K minimum to $120K maximum. Nearly every listing had a minimum salary that greatly surpassed my current salary as a music instructor. Furthermore, each one required that the intern be enrolled in some degree program in order to be eligible. This made me realize that I could be earning more money that I am now as an intern and a student studying and working on things I'm greatly interested in.
I immediately remembered University of Texas at Austin, which offers a Masters in Artificial Intelligence - evidently I could enroll for a program that starts THIS YEAR. There are several other programs that I need to look at as well, but it just may be that I need to pursue such a program! I'm very excited just thinking about this, and I'm starting to feel a sense of urgency; I need to answer this question: should I go to school online and get a Masters Degree?
6/6/2023
CS50AI
I watched most of the lecture for Week 3 - Optimization (I have about 30 minutes left). So far this lecture is much less dense than the last two. I find I’m able to keep up much better, pausing the video not very often. In what I’ve watched, I really like the concept of Simulated Annealing, which seems to have a correlation to the little I’ve done with OpenAI’s API. I’m thinking of the notion of temperature, which determines the degree of randomness used in a hill-climbing algorithm, for instance. The higher the temperature, the more random. There’s a parallel to entropy here.
6/12/2023
CS50AI
I finished the lecture and read through the lecture notes, which are always very helpful in summarizing everything. I took the quiz right after reading, scoring 4 out of 4.
Here’s the highlights:
- We can perform optimization in several ways: local search algorithms, backtracking, and constraint satisfaction. I need to take a closer look at each of these.
- Steepest-Ascent was the first local search algorithm we looked at. It involves moving from a given state to the neighboring state with the greatest increase. This algorithm will select an optional state, but it may only find a local maximum; it might not find the global maximum since it only climbs one hill.
- I found Simulated Annealing the most interesting. Annealing is the process of slowly cooling a metal down from a high temperature in order to harden it. To get around the local maximum problem, we can add a variable
temperaturethat reduces over the course of the for loop. The higher the temperature, the more likely the algorithm will choose an entirely random state over the highest neighboring state. The temperature lowers and the random jumping becomes less likely. - Node Consistency is a means of enforcing unary constraints. If variable DAY has a domain of
{Monday, Tuesday, Wednesday}, but we know that {DAY != Monday}`, then to achieve Node Consistency is to remove Monday from the domain. - Arc Consistency is a means of enforcing binary constraints, as in
{A != B}, where A and B are adjacent variables in a graph. Thus ifA == {Monday}then B’s domain is thereby restricted,B == {~~Monday~~, Tuesday, Wednesday}.
6/19/2023
CS50AI
I've been working on the Crossword project over this past week for small amounts of time. My laptop keyboard is nearly useless now as more keys have become unresponsive. I've been waiting for my bluetooth keyboard to arrive to make things smooth and get my productivity back on track; it arrived today!
I've written my first draft of the code and I don't get any runtime errors, but I also don't get the output I want. The next step is to debug and find out which functions are not performing as they should. I suspect the backtrack function is the main culprit.
6/20/2023
CS50AI
-
Poured over the backtracking search algorithm concept to understand it better. I found that my implementation needed one simple change. The important thing is I could understand why.
-
I went back and added the heuristics to
select_unassigned_variable()that were called for in the project specification: find variable with smallest domain and if there is a tie, pick whichever has the highest degree (most neighbors). To implement this, I followed the project specifications suggestion and used Python's built-insorted()method. I'm pleased with the code snippet I came up with for the first part of the function. Here it is:sorted_unassigned = sorted( ((var, len(self.domains[var])) for var in self.crossword.variables if not var in assignment), key=lambda key: key[1] )I used list comprehension inside the sorted method to create a list of tuples, which contain a variable and the number of values in its domain. I also included in the comprehension the if condition that it must be unassigned. This code snippet seems very elegant to me!
6/21/2023
CS50AI
I finished the Crossword project today. I completely rewrote the order_domain_values() function when I realized that it was doing more than it needed to do and not being used at all in the backtrack() function like intended. I went though and spruced up all my comments and submitted the project!
6/25/2023
Inventory Manager
Over the past few days, I've been modifying this project. Here's the list of changes:
- Added a forloop.counter to the take_inventory template so that an empty row will be display for every five rows. This will make the inventory list easier to read.
- Added a seasonal field to the item model in models.py. It holds a color hex code associated with each season.
- Changed the queryset in the take_inventory view from a tuple of tuple to a list of dicts. It makes the code much more readable and easier to maintain.
6/26/2023
Inventory Manager
I worked on this project for nearly eight hours straight! I think I got almost everything done. Here's the things I worked on:
- Adjusted the code in take_inventory and finalize views and their respective templates to accomodate the list of dicts. Now the code is much more readable - it's obvious what each bit of code is supposed to do.
- Improved the comments in take_inventory and finalize.
- Consolidated code, reducing database calls and redundancies in finalize. I used list comprehension more this time around simply because it makes the code more readable and concise.
- Fixed the formatting in the take_inventory template. I still need to fix the horizontal overflow problem. The content on the page overflows the navbar on the right side.
6/29/2023
Inventory Manager
I’m in the process of putting final touches on this project, and today I noticed something that could be a nuisance for the user: whenever they have to go back from finalize to Inventory to correct something, they have to reconfirm every nonzero item just as before. That’s an unnecessary hassle. I decided to look for ways to mitigate this.
I found an HTML5 object called localStorage, which allows data to persist by storing it locally in the user’s browser. I used this object to store the selected status of a given row; if the user pushed the back button in finalize, the take_inventory template would check every row as it iterates through them to see which ones, if any, were previously confirmed, and it will format them accordingly.
I do wonder if this is a more elegant solution to the persistence problem I had with the order data in general. I used the session as accessed on the backend via Django. It’s possible I’d be better off storing everything in localStorage until the user submits the order. We’ll see!
7/3/2023
CS50AI
I finished Lecture 4 - Learning. Here are my notes on the lecture. I'm trying to be more economical with my note-taking. CS50AI does a great job providing detailed notes for each lecture, so I find I can spend less energy copying everything down in the lecture and more on simply grasping the material as it is presented. In the lecture, three forms of machine learning are presented: Supervised Learning, Reinforcement Learning, and Unsupervised Learning. I wrote down all the keywords and concepts for each category, only writing the definitions where applicable. For the rest, I will rely on internet searches to strengthen my understanding.
7/5/2023
I recently started reading Artificial Intelligence: A Guide for Thinking Humans, and I find it quite captivating. Reading this book has prompted me to start making connections among various interests I’ve had over the years. I’m finding that AI is a natural evolution from those pasts topics, which include Being and Time by Martin Heidegger, the lectures of Professor Hubert Dreyfus, Phenomenology, theory of mind, criticisms of Cartesian philosophy, and Minds, Brains, and Science by John Searle. I’m excited to continue drawing connections. AI seems very much like a multi-disciplinary effort, with heavy doses of philosophy, which I really appreciate.
7/6/2023
CS50AI
Today, I began working on the shopping project for Week 4. There are a few functions for me to execute, the first of which is simply a load_data() function. It simply needs ti parse the data and cast each value to the required data type according to the specifications. I finished this function, and soon I’ll start working on the others.
7/8/2023
CS50AI
I finished the shopping project today. I found it to be one of the easier projects in this course, finishing the majority of it in one sitting! I’m intrigued by the scikit-learn library, and I want to explore it further. Perhaps I can try using it with my own applications — specifically, using KNN (K-Nearest Neighbors) Classification. Shortly, I intend to watch this video on how to implement KNN from scratch.
7/9/2023
Artificial Intelligence: A Guide for Thinking Humans
Today, I read chapter 4, and I was quite taken in with Mitchell’s explanation of Convolutional Neural Networks. I will perhaps need to reread the chapter to get a deeper understanding, but what I did understand fascinated me tremendously. Here’s a few takeaways:
- A deep neural network simply refers to a network with more than 1 hidden layer. Any layer that sits between the input and output layers is known as a hidden layer.
- In computer vision, a CNN typically sits in front of a classification model and works to simplify the incoming image for classification without compromising the most salient features.
- The CNN is comprised of layers, each containing multiple activation maps, grids of simulated neurons. Each layer performs convolutions on the image, hence the name. The book hasn’t yet explained convolutions, but a cursory web search gave me an idea: “Convolution occurs when two matrices are combined to generate a third matrix.”
- When visualizing the operations of the layers, I found the example of extracting the edges useful. Evidently, it is common for the first layer to do something like edge extraction. This information is then fed into the next layer, which extracts a higher-order matrix of data such as that if simple shapes. Hopefully I’m thinking of this correctly!
7/10/2023
CS50AI
I finished the Nim project in pretty much one sitting! It remains to be seen whether it will be accepted; perhaps I will have to revise and resubmit it. We'll see! Q-Learning, a reinforcement learning algorithm, was the main focus of this project. While I gained more understanding working on this project, I know I'll need to explore the topic further to gain a strong understanding.
7/11/2023
Azul Game AI
After completing the Nim Project for CS50AI, I started imagining what other games would be simple to train an AI on. I noticed the game Azul sitting on my shelf, and I realized it was an obvious candidate.
The object of the game is to fill out a 5X5 mosaic on your playerboard with five different-colored tiles. Each square on the board requires a specific tile. Additionally, you must acquire a certain number of like tiles, staging them next to the mosaic, before you may add one of them to the mosaic and score points. On your turn, you may draw all tiles of one color from any designated pile, called a factory, in the tableau. Any tiles not selected from the factory are reallocated to the pool in the center, from which you may also draw tiles in the same manner as with the factories.
That is the game in a nutshell: you acquire tiles to fill out your mosaic, scoring points along the way. The game ends when one player successfully places all five tiles in a given row. However, the winner is determined by the number of points accrued, not by who ends the game.
From an abstract perspective, this game loosely resembles the instruction cycle in a CPU. It is a simple game of allocating, transferring, and deallocating with an artful aesthetic. In my opinion, this makes it a great game to teach an AI, perhaps using Q-Learning (Reinforcement Learning), as in the Nim project.
Here’s my initial jottings for this project:

Implementing Computer Vision right away is more ambitious than I need to be. I’ll instead start by building a functioning version of the game for human players in the terminal. Then, I’ll set to work on the AI. After those two main goals, I’ll see about adding a GUI using pygame or some such library. Finally, if it makes sense, I’ll give the AI access to the real world game with computer vision (this will likely be very difficult - it’s unclear if I can achieve it at this point).
7/12/2023
Azul Game AI
I worked on this project for five hours straight this morning and early afternoon. I’ve been trying to settle on a design pattern, rearranging the classes, adding and removing inheritances, and etc. I think I’m very close to what I want. The game loop is nearly complete: it successfully rotates through the players and updates the attributes in their playerboards. I simply need to create win conditions and generally tighten up everything.
7/17/2023
Azul Game AI
Since the last entry, I worked almost nonstop on this project. When I finally decided on a design pattern, things more or less fell into place, but I had to comb over the code to find redundancies and test it to see where traceback errors occurred. In designing the program, I had the biggest breakthrough when I decided to represent the smallest unit, namely the Tile, as an object.
Initially, I had tiles merely represented as quantities in a list. In other words, I had a list with an index for each kind of tile; when indexed, the list would return the quantity of that given tile, which is identified by the index. Now, each element of the list is itself a list of Tile objects. Tiles can then be pushed to and popped from lists, and it’s much easier to keep track of how the tiles are moving. I’m sure my decision to represent tiles as objects results in a performance penalty, but the program runs very smoothly. I imagine I’ll find out more about how it runs when I try to train an AI model on it with reinforcement learning.
That is the next step: I will explore the Nim Project from my CS50AI class once again to see how they implemented Q-Learning from scikit-learn, and I’ll complete the Game AI tutorial on Kaggle. With those combined efforts, I think I’ll be able to figure it out, though I have no doubt it will be difficult!
7/19/2023
CS50AI
As per my new study routine, I watched the lecture without taking notes, and now I’m simply going carefully through the lecture notes provided and reviewing each concept presented. I’m expressing each concept in my own words in my notebook, sometimes going deeper than the lecture notes do. For instance, at the Gradient Descent section in the notes, I decided to explore it further.
First, I found an article by IBM; I skimmed most of it and at its behest, decided to review Linear Regression. I found this video, An Introduction to Linear Regression Analysis, and its sequel by the same channel, How to Calculate Linear Regression Using Least Square method. Finally, for Gradient Descent I landed on an article entitled Gradient Descent Algorithm — A Deep Dive. This last resource has been most helpful. I’m determined to understand how this works!
7/22/2023
Kaggle: Intro to Game AI and Reinforcement Learning
As I said I would in the entry from the 17th, I began the Game AI tutorial on Kaggle. It's a very well designed tutorial so far, and it's giving me good practice with Jupyter notebooks. The practice problem is to design an agent that plays Connect Four. I was given a simple agent that could make simple strategic moves, and the task was to improve it. For my implementation, I wanted to do something like a game tree, but I wasn't sure how to implement such a tree off the top of my head, so I instead used recursion to do something very similar to searching through a tree. Here is the code I wrote (I'm excluding the definitions of the helper functions for brevity):
def my_agent(obs, config):
---SNIP---
def recursive_move(obs, config, move, current_mark):
# Base case
temp_grid = np.asarray(obs.board).reshape(config.rows, config.columns)
obs.board = drop_piece(temp_grid, move, current_mark, config).flatten()
current_mark = (current_mark % 2) + 1
new_valid_moves = [col for col in range(config.columns) if obs.board[col] == 0]
if not new_valid_moves:
return True
for move in new_valid_moves:
if check_winning_move(obs, config, move, current_mark):
return True if obs.mark == current_mark else False
# Recursive Case
random_move = random.choice(new_valid_moves)
result = recursive_move(obs, config, random_move, current_mark)
return True if result else False
# Get list of valid moves for agent and shuffle them.
valid_moves = [col for col in range(config.columns) if obs.board[col] == 0]
random.shuffle(valid_moves)
# Check if a single move will win the agent the game.
for move in valid_moves:
if check_winning_move(obs, config, move, obs.mark):
return move
# Look ahead
for move in valid_moves:
result = recursive_move(obs, config, move, obs.mark)
if result:
return move
return random.choice(valid_moves)
Below the recursive function is the main body of the my_agent function. It does the obvious thing first by checking if any of the available moves will immediately result in victory for the agent. If not, the agent uses recursion to look ahead. One of the valid moves is added to a temporary board to see what future game states could emerge. Then, the agent checks the temporary board to see if there is a game-winning move for whichever player made the hypothetical move: if it was the agent and a winning move exists, we've found our solution. If it was the opponent with a winning move, the agent notes that by returning False. If there are no winning moves, the agent picks a random move and adds it to the temporary board, repeating the same process as above until either a winning move is found somewhere down the tree. If not, the agent ultimately makes a random move.
I moved on to the next section of this tutorial and saw that it's about designing a game tree. I'm excited to refresh myself on that! It'll probably offer a better solution that my recursive method.
7/26/2023
Azul Game AI
Bad news. The other day, I began developing a GUI for my game since I had finished the game logic. I started using pygame and as I was taking photos of game elements to use as sprites in the GUI, it occurred to me that such a design could be in breach of copyright. This realization really took the wind out of my sails. I looked into it and found that the game mechanics themselves cannot be copyrighted, but the themes, pieces, names, etc. can be. Indeed, if I were to use those images, it would probably be copyright infringement! To get around this, I'm sure I could just change all the names in my code and use my own images, but the point was to buil Azul itself, not a clone. I wanted to build this GUI so that the activity of my yet-to-be-built AI agent could be clearly demonstrated. I need to let this project sit for a while longer. Maybe in the future if I get a better grasp of pygame and I am able to sort out the copyright issue, I'll resume.
CS50AI
I received my scores from Project 4a, Shopping, and Project 4b, Nim. I got 0/1 for both, so today I spent some time debugging and refactoring the code. I was able to resubmit both projects. I hope I'll get the new scores soon!
8/1/2023
CS50AI
After working on the traffic project for the past couple days, I was able to submit it this afternoon. I had a lot of fun tinkering with a neural network via TensorFlow and the Keras API. It certainly gave me a better understanding of how CNNs work and what we mean when we speak of layers, both convolutional and fully-connected. Here's the link to my presentation video of my Convolutional Neural Network in action.
Exploring a Masters Degree in CS
For the past several weeks, I've been exploring Online Master's Degrees from various universities. I was undecided about getting another degree for some time, but now I'm confident I'm going to do it. University of Colorado Boulder is currently at the top of my list, but I'm still exploring my options. Here's a few things I like about the program:
- Admissions are performance-based, which means that if I can do the work and get good grades, I am admitted to the program. CU Boulder handles this with pathway courses: a prospective student enrolls in these courses and if their grades are good enough when they finish, they are admitted to the program.
- Working professionals are the target demographic. That includes those with a CS background and those (me) who are looking to switch careers. In the latter case, CU Boulder seems to do a great job articulating expectations. On their admissions page, there's a list of preliminary classes that a worth taking to prepare for the degree program. Those classes include Discrete Mathematics, Linear Algebra, Statistics and Probability, Intro to Programming, Trees and Graphs, and Algorithms. I already enrolled in the Linear Algebra course because it will be useful even if I choose another degree program. I will also need to take Discrete Mathematics and the Algorithms course for sure.
- The course schedule is flexible, and even start times are flexible - there are six start times per year! That means I don't need to wait for Fall 2024, as in the case of more traditional school year schedules.
8/2/2023
Getting My Desktop in Order
My SATA cables arrived in the mail yesterday and I now I can finally install my 400GB hand-me-down hard drive. I got everything working just fine, but I noticed that the health of the old hard drive was listed as Disk is OK, 221 bad sectors (44° C / 111° F). I looked into what it means for a drive to have bad sectors, and it appears it is truly bad. Bad sectors are corrupted units that can no longer properly store data. They occur as a hard drive ages, when a power failure or malfunction happens, or when a computer is improperly handled, as in the case of forced shutdowns. This means that I probably need to scrap this hard drive and buy a new SSD.
CS50AI
I started the final lecture! It's about training an AI to work with human language - Natural Language Processing. This subject is particularly intriguing because of my project idea from a couple months ago and because of all the furor around LLMs, stirred up mostly by OpenAI's GPT-3.5 and GPT-4. In the first half of the lecture, they presented some python libraries that would seem to be good candidates for my potential aforementioned journal project.
8/3/2023
Essential Linear Algebra for Data Science
Today I finished Week 1, which was all about matrix forms, e.g. coefficient and augmented matrices, and Gaussian Elimination. Most of the time was spent on applying GE to augmented matrices to find the values of the variables that satisfy each linear system in the matrix. I have to say I thoroughly enjoyed learning about and using Gaussian Elimination — it makes a lot of sense!
8/4/2023
Essential Linear Algebra for Data Science
I finished Week 2 today. Key takeaways are matrix arithmetic, especially matrix multiplication; scaling a matrix; and the identity matrix. I'm enjoying Linear Algebra so far.
CS50AI
The last lecture of this course is now finished! I'm particularly intrigued about what was presented at the end of the lecture, specifically with the nltk python library (Natural Language Tool Kit). Brian demonstrated how this library can be used to identity words by connecting them to vectors of real numbers. It's a concept that I'm going to explore further, and perhaps I'll explain it in more detail here once I've combed through the lecture notes.
Desktop Computer
My 1TB SSD arrived today, and thanks to this article, I was able to get everything moved from my old, tiny SSD to the new one with ease! It was as simple as cloning everything with pv. The whole process took 2 minutes tops. Now this desktop is in great working order: I'll likely never run out of storage since I don't use much to begin with.
8/6/2023
CS50AI
I finished reviewing the lecture 6 notes and collated all of my written notes. It turned out to be quite a process: much of my notes were taken with the Wacom Bamboo Slate, which produces SVG files (Scalable Vector Graphics), but for the latter half of the course, I switched to using my graph paper notebook for convenience. I wanted all my notes to be as uniform as possible, so I followed these steps: scanned notebook notes using Adobe Scan, vectorized the scans using a free online vectorization tool and exported them as PDFs, adjusted the sizes of the vectorized scans to match the size of the notes taken on Bamboo Slate, and merged everything together using Adobe Acrobat. I have a mild obsession with making files and folders as neat and tidy as possible! I've added the PDF to this programming log.
8/8/2023
Linear Algebra
I’ve been obsessing over linear algebra as of late. As is my wont, I’ve allowed myself to become hyper focused on it. When the Coursera course started getting confusing (it is not meant to be in-depth), I turned to YouTube and I found a fantastic playlist called Essence of Linear Algebra that breaks the concepts down very well. I’ve only watched the first two videos, but I already have a much more intuitive grasp of the concepts. The lecturer explained his pedagogy for linear algebra, that we must see how the vectors are moving in the coordinate system and thus build intuition for manipulating them with the math. I really appreciate this example-first approach.
I also found a free textbook on Linear Algebra here. I’ve been going through this mainly focusing on the practice problems, and I have to report my success on this one problem:
Page 21 1.27 Find the coefficients a, b, and c so that the graph of f(x) = ax2 +bx+c passes through the points (1,2), (−1,6), and (2,3).
Here was my work: My Work
8/14/2023
Linear Algebra
I've continued to study this subject fervently with both the Essential Linear Algebra for Data Science Coursera course and the profoundly helpful playlist mentioned above Essence of Linear Algebra. All this immersion in Linear Algebra has me excited about Mathematics again! I started casually brushing up on my Differential Calculus some more as well. Here's the main topics I've explored in Linear Algebra recently:
- Linear Transformations: it's important to visualize this geometrically, which is why I found the YouTube playlist so helpful. The videos showed just how a matrix can describe the transformation of space and consequently of any vectors existing in that space. A transformation is merely a function that takes some vector as input and returns a vector whose direction or magnitude or both is different.
- Linear Independence/Dependence: in pure math form, this was a little confusing, but as soon as I saw the geometric representation, it made sense. Two vectors are linearly dependence if their direction points along the same line (or in the case of 3 dimensions, 3 vector are dependent is they point along the same plane). They are linearly independent if they are detached, so to speak. In this scenario, the sum of the 2 vectors scaled by some scalar can reach any point in the space.
- Linear Combinations: these are directly related to the above. If two vectors are linearly independent, they are said to have an infinite number of linear combinations
- Span: this is the total number of linear combinations of a given set of vectors.
CS50AI
I submitted the final project for this class! Now I'm just waiting for my grades on three projects. If they all pass, then I'm done with this course. I've been quite pleased with the content; it's spurred me on to learn more about AI, and I think I will explore the fast.ai curriculum next!
8/23/2023
CS50AI
I received my final scores, and I passed the course! This was perfect timing since I needed to submit my application to University of Texas Austin today, and I wanted to submit the certificate as proof I completed the course. I learned so much in this course, but perhaps the greatest benefit it offered was that it made me familiar with a wide range of AI topics and nomenclature. When I encounter those concepts again, I’ll recognize them and be able to grasp them in-depth much quicker. My favorite module was Week 6, Neural Networks. Like many people, I find CNNs extremely fascinating.
Essential Linear Algebra for Data Science
I completed this course today, and though it was not intended to be thorough, it gave me a great survey of the fundamentals of Linear Algebra, and I was then able to conduct more research on my own and get deeper answers.
MSCS Applications
I submitted my application to UT Austin today! I have a couple other schools in mind too, University of Illinois Urbana-Champaign, for instance. The deadline is in October, and I plan to take the assessment exam to demonstrate I know the concepts. It is recommended that whoever plans to take the exam should enroll in UIUC’s Accelerated CS Fundamentals course on Coursera, so I enrolled in that. I hope I can get enough of it done before the application deadline.
8/25/2023
fast.ai Practical Deep Learning for Coders
I completed the lecture video for lesson 1 today. Here’s a few initial takeaways:
- Deep Learning is for everyone.
- A top-down learning format is important to really learn Deep Learning and know how to apply it to problems.
- Using resnet18 in a jupyter notebook, we can create a powerful image classifier with very little effort.
- The founder of fast.ai got involved in medicine despite knowing little about it by starting a company, Enlitic, that deployed deep learning for the detection of tumors. The model did a significantly better job than the radiologists.
8/27/2023
fast.ai Fastbook Chapter 1
Yesterday, I was having problems getting the model in the book to train. Today, with this resource, I learned to change runtime type to T4 GPU, and now it works! I’m enjoying learning the ins and outs of Jupyter Notebooks - how to use shortcut keys, bash scripts, etc. I’m following along with Fastbook chapter 1, and it’s giving me a much better understanding of the process.
8/28/2023
fast.ai Fastbook Chapter 1
I'm continuing to work through this chapter methodically. I want to resist the urge to skim through it since I know it's such good content. Here are more takeaways from what I've read so far:
- Current computer vision technology is extremely capable, and it uses Convolutional Neural Networks almost exclusively.
- When using computer vision to solve a problem, the best methods are found by thinking outside the box. For instance, a fast.ai student Ethan Sutan was able to beat a state-of-the-art environmental sound detection model using a dataset of over 8000 urban sounds converted into spectrograms and passed through a CNN. In other words, he used computer vision to analyze and correctly identify sounds!
- Segmentation is a technique in computer vision used by autonomous vehicles to pick out objects in its path, e.g. another car, a pedestrian, a building. It's primary purpose is distinguishing foreground objects from the background.
Accelerated CS Fundamentals
This course is offered by University of Illinois Urbana-Champaign on Coursera. It is used to prepare prospective students for a Data Structures and Algorithms exam, the scores of which are used in students' applications for the online MSCS program. I'm hoping to submit an application to UIUC before the deadline in October, so I need to be well underway in this course by then! This course will double as a good refresher on the C++ language. I really enjoy programming with C and C++. I need to get a better idea of the common use cases for these languages. Hopefully this course will also help me do that. Most of week 1 was simply review for me!
8/29/2023
fast.ai Fastbook Chapter 1
There is a quiz at the end of this chapter, and I'm going to answer the questions here:
-
Name five areas where deep learning is now the best in the world.
- Computer Vision, Game AI, NLP, analyzing radiology images, Autonomous Vehicles.
-
What was the name of the first device that was based on the principle of the artificial neuron?
- It was called the Mark I Perceptron and it was first built in 1957 by Rosenblatt.
-
Based on the book of the same name, what are the requirements for parallel distributed processing (PDP)?
- A set of processing units, a state of activation, an output function for each unit, a pattern of connectivity among units, a propagation rule, a learning rule, and an environment within which the system must operate.
-
What were the two theoretical misunderstandings that held back the field of neural networks?
- Minsky and Papert showed that a single layer of perceptrons couldn't do much; they also suggested that if more layers were added, their performance could be improved. However, the industry heeded only their criticism and NNs were all but discarded for 20 years.
-
What is a GPU?
- GPU is short for Graphics Processing Unit. It differs from a CPU in that it is built to handle numerous instructions simultaneously. This feature is important since it is mostly used to render 3d environments, which needs to crunch countless computations per second.
-
Open a notebook and execute a cell containing: 1+1. What happens?
- "2" is printed below the cell.
-
Follow through each cell of the stripped version of the notebook for this chapter. Before executing each cell, guess what will happen.
-
Why is it hard to use a traditional computer program to recognize images in a photo?
- We barely understand the image recognition process that occurs in our own brains, and if we were to write an image recognition program manually, we would have to describe the entire process detail by detail. Moreover, the resulting program would be very difficult to adapt for various image recognition purposes.
-
What did Samuel mean by "weight assignment"?
- The weights are variable that describe how the network will operate. They are adjusted according to the task that is required of the NN.
-
What term do we normally use in deep learning for what Samuel called "weights"?
- Nowadays, we call "weights" parameters.
-
Why is it hard to understand why a deep learning model makes a particular prediction?
- The innerworkings of the model aren't designed to be human-readable. They are only meant to be machine-readable; they generally are large vectors of floating-point values that represent probabilities that are contingent upon other probabilities and so on throughout the network. For a human to parse that data manually would be impossible.
-
What is the name of the theorem that shows that a neural network can solve any mathematical problem to any level of accuracy?
- Universal Approximation Theorem
-
What do you need in order to train a model?
- You need a dataset split into training and validation sets and sometimes further into a test set.
-
How could a feedback loop impact the rollout of a predictive policing model?
- A department might train an NN using arrest rates in a given county and use it to allocate manpower, sending more officers to the places with higher rates, leading to more arrests in those areas, which then updates the NN and reinforces the rate. Given that there is a distinction between arrest and crime rates, this feedback loop could cause a lot of trouble.
-
Do we always have to use 224×224-pixel images with the cat recognition model?
- No, that image size is by convention. The larger the image, the more precise the results, but at the cost of more computation.
-
What is the difference between classification and regression?
- Classification uses labeled data and the NN is tasked with correctly identifying the label for a given data point. Regression attempts to predict a numeric quantity such as temperature or a location.
-
What is a validation set? What is a test set? Why do we need them?
- A validation set is some percentage (often 0.2) of the dataset that is held back in the training process. This is done to avoid overfitting. Moreover, the person working on the model can also cause overfitting to occur as they tune hyperparameters to make the results of the training and validition sets align more closely. A test set is a set which is invisible to the model and the modeler such that overfitting can be avoided on both fronts.
-
What will fastai do if you don't provide a validation set?
- It will automatically create one for you.
-
Can we always use a random sample for a validation set? Why or why not?
- No, in the case of time series analysis, we would rather have the validation set be the most recent data in the series. That way we can see if the training set allows for the accurate prediction of the validation set.
-
What is overfitting? Provide an example.
- Overfitting is when your model memorizes the training data. This causes it to perform poorly when presented with new data. In other words, if a model is overfitted, it will not generalize well to other data. The whole point of training a model is to get it to generalize. For example, say you train a model to recognize cats in a picture. If the model is overfitted, then it will always identify image in the training set correctly, but it will likely make many more errors on images not in the training set.
-
What is a metric? How does it differ from "loss"?
- A metric and a loss differ in that the former is designed to be human-readable and the latter machine-readable. More specifically, the loss needs to pass into a Stochastic Gradient Descent algorithm to update the parameters of the NN. The metric merely needs to tell the human how well the NN is performing.
-
How can pretrained models help?
- A pretrained model is convenient because it eliminates a lot of work for us. Using a pretrained model, there's no need to train it from the ground up. We can simply fine tune the model to our specific needs, and this works quite well in most cases.
-
What is the "head" of a model?
- The head of a model is the component required to make a given dataset congruent with the NN. When fine-tuning a pretrained model, we need to both adjust the parameters later in the network and change the head of the model to fit the incoming data.
-
What kinds of features do the early layers of a CNN find? How about the later layers?
- The early layers of a CNN extract generally features like edges, curves, and boundaries between two colors. As we proceed, the layers generally build upon these features and extract composites of them, e.g. more complex shapes like circles, squares, etc. Finally, the later layers can extract full objects based on the combination of more simple shapes.
-
Are image models only useful for photos?
- Image models have been found to work with analyzing sound as in the case with analyzing urban sounds using spectrograms.
-
What is an "architecture"?
- An architecture is the actual function itself of the network whereas the model is the architecture plus specific parameters and purposes.
-
What is segmentation?
- Segmentation is the proces of separating objects in an image from each other and from the background. It is used extensively in the development of Autonomous Vehicle systems.
-
What is y_range used for? When do we need it?
- The y_range is used to tell our model what is its target range. It is used in regression tasks, as opposed to classification. In regression, the result needs to be a numeric quantity and the y_range confines the possibilities for that quantity.
-
What are "hyperparameters"?
- Hyperparameters are the parameters of the parameters, i.e. how quickly the parameters are adjusted during training (learning rate).
-
What's the best way to avoid failures when using AI in an organization?
- Make sure you have a test set that no one working on the model sees until the final step, when it is time to perform the models final test. This way, you ensure that both you and any third-parties also working on the model are held accountable to the actual goal for which the model was proposed. This can prevent the goal posts from being moved in the development process.
Further Research
-
Why is a GPU useful for deep learning? How is a CPU different, and why is it less effective for deep learning?
- A deep learning model has to process very large numbers of operations. A CPU can only run one instruction at a time whereas a GPU can run thousands thanks to its thousands of cores. This significantly expedites training for a Deep Neural Networks.
-
Try to think of three areas where feedback loops might impact the use of machine learning. See if you can find documented examples of that happening in practice.
- Perhaps the most significant example of a negative feedback loop in popular culture is in social media, where users are increasingly fed the content with which they are most likely to engage, sending them deeper and deeper into an echo chamber. This can affect, and already has affected, the political climate, pushing more and more people to radical ideas.
- Negative feedback loops can occur in Recidivism models, which try to predict whether a given inmate is likely to return to crime upon release. The problem here is that bias based on race and sex could factor into the prediction, thus reinforcing itself.
- What's an example of a positive feedback loop? Suppose there's a model that predicts a student's grade potential based on certain activities. If the student performs well, they will see their grade potential increase, and this increase could promote further improvements in their activities. This may be a silly example, but I'm trying to think of positive cases since they seem harder to imagine than negative cases.
8/30/2023
fast.ai - Practicing on My Own With Google Colab and Kaggle Datasets
It would be easy to rush through the content in fast.ai given that it is not graded and students have access to all of the course content all at once. I'm fighting the urge to move quickly by practicing with the material that was covered in lesson 1.
I started by creating a new Jupyter notebook in which to build an image classifier much like the Cat Classifier in Fastbook. However, I wanted to change it up, so I used the cars dataset, executing path = untar_data(URLs.CARS). I encountered some problems that seem to be related to the dataset itself. I think it might be in disarray at the moment. Nevertheless, I have no doubt there's something I'm doing wrong as well. I decided to move on from this practice as I'm not trying to worry about fixing a problematic dataset.
Next, I decided to try fetching a dataset from Kaggle. I settled on the Bottles and Cups Dataset. First, I learned how to import the dataset from Kaggle into Google Colab via this article, Importing Kaggle Datasets into Colab. Let's go one cell at a time:
I wanted to remove the laundry list of pip3 install messages and piping the results to /dev/null was the answer.
# Install required libraries
# Redirect logs to /dev/null to silence output
!pip3 install opendatasets > /dev/null
I used opendatasets to download the dataset from Kaggle. The dataset was stored in a folder named the same as the final directory in the url, https://www.kaggle.com/datasets/dataclusterlabs/bottles-and-cups-dataset, so I did this:
# Extract the directory at the end of the url
_, tail = os.path.split(url)
path = '/content/{}/images/images'.format(tail)
print(path)
The labels for each image are stored in xml files, so I used the Element Tree XML API to extract them. I really don't know if this is the right way to go about it yet, but the function I wrote works.
def get_labels(fname):
fname = fname[:fname.index('.jpg')] + '.xml'
tree = ET.parse('/content/bottles-and-cups-dataset/annotation/Bottles and Cups anotated/{}'.format(fname))
root = tree.getroot()
for elem in root.iter('name'):
return elem.text
I left off at the ImageDataLoader object since it isn't working yet. The current problem is that some of the labels are missing for the training data (why do I keep encountering problems with these data sets?).
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=get_labels, item_tfms=Resize(224)
)
9/3/2023
Accelerated CS Fundamentals
As much as I want to spend more time on the fast.ai curriculum, I need to make this course the priority for this month since it regards my application to University of Illinois Urbana-Champaign, which I intend to send by the deadline in mid-October. To strengthen their application, prospective students can take a Data Structures Exam, preparing for it with this class on coursera. That's what I'm doing. Here's some highlights from the past few days in this course:
-
I'm glad to be coding with C++ again after so much time spent with Python. It's a nice juxtaposition.
-
I'm reminded the difference between a pointer that points to memory on the heap and one that points to memory on the stack.
// Heap int *ptr = new int(10); // Stack int n = 10; int *ptr = &n; -
This course has helped me understand the reference variable much better. The reference is simply an alias of some bit of memory. It refers to the exact same value at the same address as the variable referenced.
int n = 10; int& nRef = n; -
I solved the Tower of Hanoi problem! While the premise of the problem feels familiar, I don't believe I've ever tried to solve it before. I had a blast working through the logic, trying to find a predictable pattern in the solution, and then converting my pseudocode to valid C++. Here's some artifacts from my process:



Ultimately, I was able to uncover one simple heuristic: the smallest cube must be moved 1 space to the right in a loop every other move. From there, everything happens predictably. The moves in between are simple because there’s only ever one valid option. I was quite pleased when I discovered this! My code can be found here. In the .cpp file, I make it clear what code is mine.



9/6/2023
Accelerated CS Fundamentals
I hopped over to Lift Bridge Coffee in downtown Tacoma this morning and worked through the remainder of Week 4. I took the quizzes and completed the Image Transform project: I enjoyed working on it as I've tried my hand at image manipulation with C in the past. I was glad to try it again with C++ and with some guidance. I'd like to look over the code again and see if I can expand on it further for my own purposes. It really is great to use C++ again! I briefly began the second course of this specialization.
fast.ai
I watched most of Lesson 0, entitled How to fast.ai. It is designed to help students get the most out of the course. Very quickly, Jeremy answered many of my questions, which cropped up while I was completing Lesson 1. After finishing Lesson 0, I plan to go back to Lesson 1 and build a simpler model than the ones I was trying to build. Moreover, I'll use the Anki flashcards to make sure I understand everything. Here's a few key takeaways:
- Build a project while taking fast.ai.
- In Colab, Open Notebook allows us to open notebooks from GitHub.
- Matrix multiplication is the main bit of Linear Algebra required for Deep Learning Practitioners.
- Start blogging! Write what me from 6 months ago would want to read.
- Machine learning code is HARD to write!
- Enter a Kaggle competition. Jeremy really stresses doing this.
9/7/2023
fast.ai
I'm very pleased! Last week when I was stumbling through creating my own models, I kept trying to use ImageDataLoaders.from_name_func() on datasets that weren't compatible. Today, after scouring the fastai docs, I found the section on ImageDataLoaders and read up on the various methods available in this class. I found the from_folder method and realized this would work for the MNIST dataset. Indeed it did. I'm finally starting to feel like I have a grasp of this stuff! For the next project, I'm going to try to fix what I did wrong in practice2.ipynb. Here's some other ideas for the future:
- Use scipy.signal.spectrogram to convert soundclips of guitar hammer-ons to spectrograms. I want to see if it is possible to train an image classifier to recognize this particular legato technique on guitar!
9/9/2023
fast.ai
I'm feeling much more confident with the fastai library. There's a ton for me to discover with it since I've really only dabbled with image classification, but I'm happy so far with what I do know. Today, I successfully built the first iteration of the guitar hammer-on model. It works! However, I'm still skeptical about my results. Before I get into that, let me walk through the steps I took to build this thing.
- With my Rode NT-USB Mini condenser microphone and Audacity, I recorded one long track of hammer-ons. First I went along each string performing half-steps, then whole steps, and finally minor 3rds. I did the same procedure for melodic intervals that did not include hammer-ons.
- Using the
Truncate Silenceeffect, I was able to get each sample more or less equidistant from one another. - The
Silence Findertool automatically placed labels throughout my track wherever silence (defined as less than -25 dB) was found. Finally,export multipleallowed me to discretize each sample according to the labels and export them individually. - In my project folder in VS Code, I moved all the hammer-on soundclips into a folder name hammerons and all the non-hammer-on soundclips into non_hammerons_.
- I used the Python3 shell to rename the nearly 400 samples to more descriptive names - false-classical-34.wav and true-classical-2.wav.
- Making use of
scipyandmatplotlib, I wrote a python program to iterate through the directories and convert each wav file into a spectrogram. These I saved in separate directories: true for hammer-ons and false for the others. I created a new repo on github and pushed this new dataset. - In Google Colab, I did the usual setup for training and fine-tuning a model with fastai. I connected my drive
from google.colab import drivethendrive.mount('/content/drive'). I pulled my dataset from github. - For the
ImageDataLoaderI used thefrom_path_func()to organize and label my input spectrograms according to the names of their parent folders. - From here, it's been a matter of experimenting with different CNN architectures (I started with resnet34, went to resnet152, and settled on resnet18, which to my surprise gave good results) and altering the number of fine-tuning epochs.
To test the model further, I recorded a couple more hammer-ons using my phone. When I ran them through the model, it failed to categorize them properly several times. Recording with my phone, I notice that the audio is processed much differently than with my condenser microphone. The audio from the phone seems to be inherently louder, so it's possible the model is thrown off by the difference in loudness. I'm just getting started with this dataset. I need to include samples that are loud, quiet, clean, sloppy, clear, noisy, electric, acoustic, nylon, steel, etc. If I can properly diversify the dataset, I think I can dramatically improve the results. Maybe I'm thinking about this wrong - I'll find out!
9/10/2023
fast.ai
Today, I focused on cleaning up the jupyter notebook for the Guitar Legato Classifier. I wanted to push myself to post the project in the fast.ai forums. I need to become more social in my endeavors if I am to find opportunities to make a career out of this stuff. It took me much longer than expected to spruce up the document, mainly because I found that Kaggle made it easier to share notebooks, so I needed to migrate my notebook there. I was a good yet frustrating learning experience. I now think I have a better handle on Kaggle: I really appreciate how easy it is to add datasets into the notebooks whereas with Google Colab, you must connect the notebook to the Drive and then navigate the directories from there. Kaggle makes this whole process much more streamlined. In terms of interface, I still prefer Google Colab - it just seems much more snappy, for lack of a better description. Moreover, it's kernel seems to run more smoothly and quickly.
9/11/2023
fast.ai
Finished the Lesson 2 Lecture. I was thrilled to get an introduction to Hugging Face Spaces and Gradio! I'll waste no time in building my own spaces and showing them off. perhaps I'll build custom UIs in JavaScript and host them on my personal website, as Jeremy Howard suggested. I had a bit of trouble following with the Gradio and Spaces example in the lecture; when I tried to git push the codebase to Spaces, I kept getting an error saying the .pkl file, which is the model, the heart of the program, was too large (>10MB). Searching online, I found that the solution was to use git-lfs to track the large files and then try pushing. Initially, this didn't work either. Someone else suggested simply deleted the Space and creating a new one. This proved to work. I was finally able to push the codebase after much suffering. Everything worked! I really like the way Gradio + Spaces looks. It will be a great way to prototype or demonstrate proof of concept. The next step is to read the second chapter of fastbook and follow along with the code snippets.
9/12/2023
Accelerated CS Fundamentals
Continued in the second course (Ordered Data Structures) of this specialization. I spent the most time on a video about Run-Time Analysis. To explain run-time analysis, the lecturer contrasted two data structures, the Array and the Linked List. He showed that to increase the size of an array by 2 every time it becomes full takes O(n^2), but if instead the size of the Array is doubled whenever it is full, it take O(n). With Lists, he demonstrated that to append or prepend to the list takes O(1), which is definitely one of its strengthes. However, insertion in a List is O(n) since we have to iterate through each element to get to the desired location for insertion (it is the same for deletion).
Here were some of my thoughts: I reasoned that vectors use the doubling in size strategy to dynamically grow based on the needs of the program. O(1) can be thought of as given n items, it will take 1 operation to accomplish the task in question. O(n^2) can be thought of as given n items, it will take n^2 operations to accomplish the task in question.
O(1) is Constant Time.
O(n) is Linear Time.
O(n^2) is Polynomial Time.
If we sort an Array, we can then perform Binary Search on it, which takes O(log n) - much better than the Linear Search we would have been forced to use on an Unsorted Array. Unfortunately, we cannot use Binary Search on a List.
9/13/2023
fast.ai
I began reading the fastbook chapter for lesson 2, and I'm taking notes as I go. So far, I've written the following:
- It's easy to underestimate both the constraints and the capabilities of deep learning. "Gradually roll out models so they don't create significant risks."
- Pick a project, get started, work out the details as you go, build it end-to-end quickly, and repeat the pattern.
- Things deep learning is good at:
- Computer Vision (Object Recognition, Detection, Segmentation)
- NLP (Classifying Text, Generating Context-Appropriate Text)
- Combining Text and Images - Multimodal (Generating captions for images and videos)
- Tabular Analysis (Time Series and Tabular Data)
- Recommendation Systems (Typically represented with a giant sparse matrix with user ids for rows and product ids for columns. The systems then fills in cells for a given user based on other users who have similar purchases in a process known as collaborative filtering)
- Analyzing audio with Computer Vision using spectrograms.
Guitar Legato Classifier
Thinking about the models failure to identify sounds captured with an iPhone, I began exploring how the iPhone handles audio input. I found that it is rather heavily compressed to allow for a wide range of recording environment (it is meant for all-purpose recording after all). The best solution will be to record an additional set of sample all on an iPhone, but as a more expedient solution, I tried further processing the audio clips I already have. I added a compressor, setting
threshold to -24dB
noise floor to -40dB
limiting ratio to 5:1
So far, this has not improved the model with respect to iPhone recordings. However, I noticed that the model improved overall with the added spectrograms of the compressed audio clips. I changed the architecture to resnet50 and reduced the number of fine-tuning epochs to 10.
9/16/2023
fast.ai
I'm going to answer the quiz questions at the end of the chapter as I go. Here they are!
- Provide an example of where the bear classification model might work poorly in production, due to structural or style differences in the training data.
It might work poorly when incoming data is not captured well, is partly out of frame, askew in some way, or really any suboptimal representation that may not have been present in the training data. It's difficult to account for all the ways data may be presented to the model in production. - Where do text models currently have a major deficiency?
They hallucinate, which means they will confidently answer questions incorrectly. - What are possible negative societal implications of text generation models?
They can be used to spread misinformation at a much larger rate since social media posts and other forms of mass interaction can be automated and tailored a desired message. - In situations where a model might make mistakes, and those mistakes could be harmful, what is a good alternative to automating a process?
Instead of automating a task, say determining which patients are low risk AND sending them home, the system could merely augment the decision making of a human. A doctor could be given the models predictions and use them to inform their, not make the decision for them. - What kind of tabular data is deep learning particularly good at?
It is good at recommendation systems and the technique associated, collaborative filtering. - What's a key downside of directly using a deep learning model for recommendation systems?
They only tell a user what they might like, not what might be actually useful to the user. If I really like the author Philip K Dick, the system might recommend his novels to me. This is not that helpful because I'm already aware of PKD's books. It would be better if the system could recommend books that bear some indirect relationship to PKD's writing. - What are the steps of the Drivetrain Approach?
Define objective; determine what inputs can be manipulated; determine what data is needed and what is already possessed; and build the model. - How do the steps of the Drivetrain Approach map to a recommendation system?
Objective: drive additional sales by recommending things to customers that they wouldn't otherwise purchase. Lever: ranking of the recommendations. New data must be collected to drive new sales. Finally, for building models, two models could be built: one for purchase probabilities without recommendations, and one for those with recommendations. The difference between them is a utility function: when it returns a large difference, we know the recommendation will likely drive a new sale, and when it returns a small difference, we know the recommendation is probably showing the customer something they're already inclined to purchase and is thus redundant. - Create an image recognition model using data you curate, and deploy it on the web.
- What is
DataLoaders?
DataLoadersis a class that stores DataLoaders, making them available as training and validation sets. - What four things do we need to tell fastai to create
DataLoaders?
What kind of data we're storing, how to get the data (where it lives), how to set labels on the data, and how to create the validation set. - What does the
splitterparameter toDataBlockdo?
The splitter parameter tells the DataLoader how to apportion the training and validation sets. If it is provided with a seed, it will apportion them the same way every time the DataLoader is instantiated. Passing an argument to the parametervalid_pct, determines what percentage of the data should be set aside for validation. - How do we ensure a random split always gives the same validation set?
By specifying a seed. Random number generators aren't truly random (they're pseudorandom), so if we give them the same starting point every time by settingseed=42for example, then we will get the same validation set every time. The important thing is that it will have been pseudorandom the first time. - What letters are often used to signify the independent and dependent variables?
'X' is used to signify the independent variables and 'Y' the dependent variables. - What's the difference between the crop, pad, and squish resize approaches? When might you choose one over the others?
Each approach is meant to adjust an input image to the dimensions expected for the input tensor (all images must be the same dimensions). The pad method pads the image on the x or y axis, depending on whether the image is tall or wide; the squish method squishes a tall image along its y-axis, or a wide image along its x-axis to that it is square with the input tensor; and the crop method takes an input-tensor-sized portion of the image. It seems that cropping is the preferred method since it preserves information without giving the model meaningless empty space, as in the case of padding, and it doesn't skew the image, as in the case of squishing. However, I could imagine a situation where squeezing is used because the warping of the image is not a concern and we don't want to crop and lose any of the perimeter of the image. - What is data augmentation? Why is it needed?
Data augmentation is the process of warping, skewing, or tilting the perspective of the image to create scenarios that are likely to happen in production. For example, you have an image classifier app designed to recognize faces in a photograph simply by pointing a phones camera at it. A user might quickly snap a photo of the photograph with their phone without considering how well they captured the image. You want the classifier to be able to work nonetheless. tl;dr - You want the model to work in production even under suboptimal conditions. - What is the difference between
item_tfmsandbatch_tfms?
item_tfmsworks on one item at a time whilebatch_tfmsworks on a whole batch at once using the GPU. - What is a confusion matrix?
A confusion matrix is a data cleaning tool, showing how the models predictions may be incongruent with the actual data. There's a column and a row for each category and the columns represent what the model predicted and the rows represent the correct labels. Thus, the cells represent the intersection between the two. We can see where the model correctly predicted the categories in the top-left to bottom-right diagonal, and where it miscategorized everywhere else. - What does
exportsave?
It saves a .pkl file to the kernels directory. - What is it called when we use a model for getting predictions, instead of training?
It's called inference. - What are IPython widgets?
IPython widgets allow us to run a simple GUI in Jupyter Notebooks. With them, we can spruce up our models and make them easier to run. - When might you want to use CPU for deployment? When might GPU be better?
When you are processing one user's image at a time, which is often the case, then a CPU is the most cost-effective and efficient. If your app is quite popular and needs to process numerous images at once, you can batch the images together and process them with a GPU to be more efficient. - What are the downsides of deploying your app to a server, instead of to a client (or edge) device such as a phone or PC?
- Your app always requires an internet connection.
- Users may be concerned about the privacy of their data being sent to the server.
- Since a connection to the server must be established to use the model, latency can be an issue.
- Scaling a server to accommodate increases in users is more complex than scaling an app that runs its logic on the client-side, mustering the compute resources of the users.
- What are three examples of problems that could occur when rolling out a bear warning system in practice?
- The model could fail to identify a bear since the training set cannot possibly account for all the variability in practice. It could also falsely identify a bear. (Out-of-domain data)
- A models inference could sometimes be too slow to be useful - slower than simply having a park ranger observe the video footage.
- The operation of the model could influence the system it is trying to predict and thus skew the data, rendering it unhelpful, misleading, and/or dangerous.
- What is "out-of-domain data"?
Out-of-domain data is data presented to the model that is very different from the data used to train the model. In the case of our bear classifier, if we used only images taken in the daytime, then any footage gathered at night would be out-of-domain. - What is "domain shift"?
Domain Shift is when the data presented to the model in production gradually changes over time, making the model operate increasingly poorly. With the bear classifier, this might occur if the habits of the local bears change. Maybe they stop moving along their original pathways, where the detection system is operating; worse, maybe an influx of a different predator occurs in the area, perhaps mountain lions. The detection system would either become useless or perhaps problematic if it occasionally falsely identified mountain lions as bears. - What are the three steps in the deployment process?
Using the bear detector as an example.
- Manual Process: the park ranger continues to monitor the video footage while a classifier model operates in parallel. The model is not used to inform any action at this stage.
- Limited Scope Deployment: the model is now used to inform decisions, but it is limited to one location and the veracity of its predictions is checked by the park ranger. In other words, the model augments the tasks of the park ranger, but only in one surveillance location.
- Gradual Expansion: the use of the model is expanded, solid reporting systems are put in place to monitor any dramatic changes in model performance, and the supervisors of the model remain alert to anything that could go wrong with the system.
9/19/2023
The last couple days have been a ride. Yesterday, I began brainstorming about what I could do to practice the principles explored in Lesson 2 of Practical Deep Learning for Coders from fast.ai. The notion of exploring red tides came to me rather spontaneously. I wondered, can I build an image classifier that takes in satellite images of coasts and determines if there is a red tide, or Harmful Algal Bloom, present? I spent a large portion of the day conducting research to answer that very question. I quickly found out the answer is yes because it had been done, more or less. I found out about the Cyanobacteria Assessment Network App, which measures cyanobacteria content of water bodies for phone users. It's unclear whether the app makes use of machine learning; I'm inclined to think it doesn't. The images from the satellite can be filtered, allowing for the color signature of HABs to emerge.
I learned a lot doing this research. I found out that images from the Sentinel satellites are available as data products for free from dataspace.copernicus.eu and other sources. On their website, I found I had a lot of control over what kind of data I wanted to capture from the satellite imagery. They have an interactive scoping tool (for lack of a better description) that lets you select the precise location you want to explore; then, you can search the list of data products that are available for that region. I also learned about Sentinel-3's OLCI (Ocean Land and Color Instrument), the primary tool in detecting cyanobacteria growth from a satellite.
I decided to put this project on hold for now since I found out it is so well researched. The more I think about it the more I find I should probably just make an image classifier anyway since the practice alone would be a boon. The same day, I moved on to another project, which I'll describe next.
Guitar Pitch Classifier View it on Codeberg
Initially, I thought this project would use deep learning, but so far it hasn't needed it. Perhaps that will change as it becomes more sophisticated. This project is somewhat of a tangential effort to the Guitar Legato Classifier, which actually does use deep learning. Instead of classifying how notes are played, I wanted to classify the notes themselves. I figured it couldn't be too hard given that there are a plethora of guitar tuning apps that do just that, in real time no less! Here was my process:
- Discover main ingredient, the Fast Fourier Transform, which takes an audio signal and stratifies it into its collection of simple waveforms. What makes a sound complex is its combination of waveforms of varying amplitude, periodicity, and frequency. Further, a sound gets its unique timbre, or tone color. Every sound has a fundamental accompanied by the range of the harmonic series, but sounds are distinct as a function of which harmonics are most eminent. FFT does a great job to disentangle all these waveforms, allowing me to isolate the one with a given frequency I'm interested in.
- Successfully analyze a sound clip with one note played. It might be simple, but I was quite pleased with my implementation of binary search as a means to discover what 12-TET pitch the input frequency most corresponded to. I knew I couldn't count on the input frequency being exacted equal to the correct frequency given that the data was floating-point numbers and that the input frequency may be coming from a guitar not perfectly in tune. This ruled out the use of a hash table. Instead, I used a list of tuples initialized ahead of time,
initialize_TET_notes(), that maps out all 88 notes on a piano, matching the 12-TET frequencies to their musical note names. Themap_frequencies()function then uses binary search to match the input frequency with that which most closely corresponds. I was happy to find a tangible use for binary search in my own program! - Allow the program to analyze a clip with many notes. I went on a fools errand here. I tried to accomplish this goal by altering the logic of the
extract_frequency()function, which identified a single note. In the long run, I realized I needed to scale the use of the function, tokenizing the input audio beforehand according to each discrete noise and then passing those tokens to the function one at a time. This is the method that won out in the end. Perhaps there is a more elegant solution, but that will only come when I have a much clearer understanding of Fourier Transforms and Digital Signal Processing. - Add a means to translate musical notes into strings and frets on a guitar fretboard. I created a new py file,
guitar.py, and created a dictionary that has note names for keys and a list of frets where those notes can be played. I enjoyed analyzing the fretboard in this way; it actually gave me a deeper musical understanding in the process! The very lowest and highest notes on guitar are only available on one fret. The notes in between have more options - it looks sort of like a normal distribution. Of course, it's not very useful to just have a list of possibilities; the functionplot_path()takes the possible ways to play the melody and chooses one according to criteria such as how far apart the frets are, what primary position should the melody be played in, etc. These parameters can and should be tweaked. There's a lot of further fine-tuning that should happen here. - Add a GUI. I've not accomplished this step yet. I'm trying to determine the best method and framework. So far, I'm thinking it might be easiest to use a web browser and HTML/CSS and JavaScript.
9/21/2023
Accelerated CS Fundamentals
I've been working on the Linked Lists and Merge Sort Project from Week 1 of course 2 in this specialization, and even though it is all material I've covered before, I found myself extremely frustrated. I kept getting segmentation faults trying to insert a new node into a doubly-linked list. I should have been an easy operation, but I've been spoiled by Python for a while now, and I've temporarily lost the touch with pointers. Here's the code that finally worked:
Node* current = head_->next;
while (current) {
if (n->data <= current->data) {
n->next = current;
n->prev = current->prev;
current->prev->next = n;
current->prev = n;
break;
}
}
current = current->next;
My only mistake: instead of current = current->next;, I originally wrote current++;, effectively moving the pointer to some garbage value. Linked lists are not composed contiguously in memory. Instead, as we follow the pointers, we will likely jump around memory addresses in a haphazard manner (this isn't entirely accurate, but it paints the picture). If I merely increment the pointer, it's possible I'll end up pointing to a node in the list, but that would just be circumstantial since nodes aren't inherently contiguous. More likely, the pointer will simply point to some unallocated memory, a garbage value. And that's exactly what happened. This simple bug eluded me for longer than I care to admit. I'm glad for this review of C++!
9/23/2023
Accelerated CS Fundamentals
Over the past couple days, I finished Week 1 and 2 of Course 2 in the specialization. It was about the Tree data structure, how binary trees can be used to create dictionaries, and the pros of a binary search tree for lookup. A linked list has a best case runtime of O(n) for lookup, but a binary search tree has a best case runtime of O(log n). It's noteworthy to compare the two since they both consist of nodes connected by pointers, so you could say that the BST "improves" upon the structure of the linked list. However, BSTs come with their own complications: it's much less straightforward to remove nodes from a BST than it is from a linked list. For instance, if a tree node has two children, then the process is multi-step; for the node to be removed, find its In-Order Predecessor, swap with IOP, and remove the node from its new location (note: its new location might be another node with two children - for every such case we can run the aforementioned process recursively or iteratively).
Over all, I found the segment on Trees very useful since they are the data structure with which I have the least experience. Now I understand them much better. What's more, I likely have a real-world use for them right away: my Guitar Pitch Classifier likely needs something like a tree (what kind I'm not sure yet) for its plot_path() function. The function currently runs without such a data structure, but I'm sure it will need one to be sufficiently optimized.
10/6/2023
Applying to UIUC
Alright, I figured I should update this log on what I've been doing for the past two weeks. The deadline to submit an application for UIUCs Online Masters in Computer Science is October 15th. On Sunday of this week, I finally finished up my Statement of Purpose, which took me very long to write. I had to figure out how to distill everything I've done in the past two years, condensing it into 1000 words. Once I finished it, I submitted the application. In these two weeks of unaccounted time, the first was all about finishing that essay (which can be found here) and making more progress in the Accelerated CS Fundamentals specialization on Coursera.
Accelerated CS Fundamentals.
The second week has been all about finishing the Accelerated CS specialization. The first two course in the specialization were mostly review, so I completed them quickly. The final course has presented more new material, so I've had to take my time. Here's a list of the topics we've covered in the specialization:
- A tour of the basics of C++.
- Examination of Arrays and Linked Lists, the foundation of most Data Structures.
- Resizing an array by doubling as the most efficient strategy - O(n).
- O(1) Constant Time; O(n) Linear Time; O(n^2) Polynomial Time.
- Queues and Stacks..
- Insertion Sort and Merge Sort.
- Binary Trees (perfect, full, and complete).
- Tree Traversals: Preorder, In-Order, Post Order.
- Binary Search Trees (balancing through rotation).
- AVL Trees (BSTs with rebalancing upon insertion and removal).
- B-Trees.
- Heaps: min-Heap (heapifyUp and heapifyDown).
- Heap Sort.
- Hash Tables and Hashing: collision handling with separate chaining, probe-based hashing, or Double Hashing.
- Disjoint Sets and UpTrees (path compressions).
- Graphs: Edge lists, Adjacency Matrix, Adjacency List.
- Graph BFS Traversal (Breadth First Search) and DFS Traversal (Depth First Search).
- Minimum Spanning Trees.
- Kruskal's Algorithm and Prim's Algorithm
In addition to completing this specialization, I've been making flashcards with the help of Anki. I hope to finish Accelerated CS this week and then spend Monday and Tuesday making flashcards and studying for UIUCs DSA Exam.
10/7/2023
Accelerated CS Fundamentals
I completed this specialization today! It feels like quite an accomplishment considering how in-depth the courses went in short spans of time. This specialization was meant to be a preparation for UIUCs Data Structures and Algorithms Proficiency Exam, and now that I'm done with it, its time to go through my notes and make sure I understand everything that was covered. I've already been doing this, as I outlined above. I've been making flashcards with Anki, and reviewing concepts with the geeksforgeeks app. I might also try some implementations of the Data Structures and Algorithms on my own. The exam is on October 11th, so I need to keep studying!
10/9/2023
Data Structures and Algorithms Proficiency Exam
I finished making flashcards, ending up with 106 in total. When I'm finished studying for this exam, and I've made all my edits to the flashcards, I'll add them to this programming log. By the end of the day, I have reviewed every card several times.
Addendum (10/17/2023) - My flashcards can be found at data_structures_and_algorithms.xml. This xml file can be imported into the AnkiApp for use.
10/10/2023
Data Structures and Algorithms Proficiency Exam - heapsort.cpp
Instead of reviewing more flashcards, I tried my hand at building heapsort. I was able to intuit the logic pretty well, but where I got stumped, I consulted GeeksForGeeks. Building this simple algorithm, I had a chance to get more familiar with the nuances of C++ like overriding functions and using friend functions. A friend function is "A friend function of a class is defined outside that class' scope but it has the right to access all private and protected members of the class. Even though the prototypes for friend functions appear in the class definition, friends are not member functions." tutorialspoint.com. I've linked to the final result of my program in the header for this entry.
10/13/2023
Mastering DSA Using C/C++ - Udemy
I started this course up again. UIUCs Accelerated CS Fundamentals course gave me a great overview of DSA, and I wanted to follow that up with more study — that’s when I remembered this course was archived in my Udemy account. I don’t intend to progress through this course linearly. Instead, I’ll cherry-pick the lessons that best fill in the gaps in my knowledge.
Today, I watched a few of the videos in the introduction section. I learned more specific definitions of “database,” a data structure designed to live in storage but which can be brought into main memory for data manipulation, and “data warehouse,” an array of disks that store legacy data (as opposed to operational data).
10/17/2023
Rubik's Cube Solution Generator
For the past two days, I've been writing a program in C++ that will take an unsolved state of a Rubik's Cube and generate a list of required moves for the user to make in order to solve it. I chose this project for a couple reasons: first, it is helping me get much more familiar with C++, and second, it will segue back into the Practical Deep Learning for Coders course. I intend to take images of an unsolved Rubik's Cube as input. To do this, I'll build an image segmentation model that can take an image of a face of a Rubik's Cube, segment it into its individual squares, and determine their color. In this way, my C++ backend will be able to receive this input data and operate on it, generating a list of moves to arrive at a solution.
With this project, I can practice with my Deep Learning and Python skills (building and training a model, exporting the .pkl file, deploying in a HuggingFace space using Gradio); C++ syntax, libraries, and design patterns; data structures and algorithms (determining how to represent and operate on the Rubik's Cube in memory efficiently); and with integrating two different programming languages, Python and C++.
So far, my design process has gone like this:
- Decide how to keep track of edges and corners, where they should be and where they are. I used xyz coordinates, with the invisible center cube as the origin.
- Calculate many moves an edge or corner is away from its target using the floor of a
Euclidean Distanceoutput. Considering an edge that needs to be moved, we can get its Euclidean Distance to its target, get its adjacent edges (possible moves), and then determine which one to make based on which one decreases the distance the most. (There will be some shortcomings with this approach - moves that disrupt solved edges and corners shouldn't be chosen when a move that doesn't disrupt is available) - When getting adjacent edges, my initial design was to calculate them using a function called
get_adjacent_edges(). The trouble with this method is it doesn't tell the program how to get to the various adjacent edges. I'm working on a solution to this that involves a directed graph of the edges mapping out their adjacencies as well as what cube manipulation is required to move to each. - For making the actual moves themselves, I decided to keep track of the edges and corners with a class called
Face. This class organizes edges and corners in a circular doubly-linked list. Additionally, it has a list of pointers to affected faces so that whenever a rotation is performed, the adjacent faces will have three of their cubes updated.
10/23/2023
Rubik's Cube Solution Generator
I made some significant changes to the program over the last week, and today I finally ended up with a workable first step: the program successfully moves the first four edges in place to solve the white cross in a function called solveWhiteCross(). However, it does not yet ensure that the edges will be oriented correctly. It won't be hard to write a function that rotates any disoriented edges; what will be hard is identifying which edges are disoriented to begin with. That entails keeping track of the orientation of every cube even while they move around. I've not yet deduced the solution to this, but I suspect it will involve some form of modular arithmetic.
Here's a few of the changes I made over the last week:
- No more circular doubly-linked list for the faces. Instead, all cube components simply contain keys that allow them to perform lookups in a
std::mapcalled state, where all the information about edge and corner location resides. This is much cleaner than my previous implementation, which required numerous steps whenever a move needed to be performed - it was so convoluted that I couldn't get it to work fully! - I defined a list of global constants, assigning
RubiksCoordvalues to variables named after the colors on a given cube: white/orange becomesconst RubiksCoord WO = {-1,0,1}. This makes my life much easier since I can work with more readable variables. - I implemented another
std::mapthat functions much like an adjacency list in a graph, but I'm not sure I can call what I made a graph. Now, it takesO(V)time, where V denotes adjacent edges. (I know it's a little backwards to be speaking of edges that aren't really edges in the sense of a graph. There's a namespace problem with the Rubik's Cube and Graph nomenclature!)
There's much more to do with the backend, but I decided it would be much easier to perform tests if my frontend were complete - that way I can easily get new unsolved cube arrangements into the backend without having to hardcode every test. Here's what I've been discovering so far:
- I need to implement some form of Image Segmentation, which seems to be the next step up in precision from Image Classification, which is all I've done so far in
Practical Deep Learning for Coders. - First, I used makesense.ai in an attempt to segment my Rubik's Cube images. When starting the annotation, I selected
Object Detectionand I used the polygon to to draw around the edges of each colored square on the cube. I completed all 24 images with that painstaking process. To export the annotation, my only option for file format was aCOCO jsonfile, a single file which contained the annotations for all the images. I learned that COCO stands for Common Objects in Context. It is a particular usage of json files that started with Microsoft'sMS COCO Datasetin 2015. Its specific json annotation format became the standard for many Object Detection datasets. - I uploaded my freshly-annotated dataset to my Hugging Face profile, and then set about learning how to import and manipulate the dataset in Google Colaboratory.
- With the help of this Hugging Face Dataset Walkthrough, I learned the basics of manipulating datasets in Colab. Hugging Face's
datasetlibrary is quite capable! I found out how to get my dataset into a dictionary with everything neatly organized according to train, images, annotations, categories keys. I realized this is not exactly what I wanted however; I needed instead to download the dataset to my working directory in Colab. I accomplished this simply with!git clone https://huggingface.co/datasets/seandavidreed/rubiks_cube_segmentation. - Getting my images and labels into the
DataLoadersfrom fastai was the next challenge. It was here that I began to realize something was wrong with my annotations. Every example I found showed that the labels were the images themselves with the color masks over each discrete object. My dataset only contained the singleCOCO JSONfile, which did not behave as expected when I loaded it into other image annotation software (LabelMe, for example). I discovered that I had annotated my images according to Object Detection, not Instance Segmentation, which is what I needed. This article, Instance Segmentation vs Object Detection. - Most recently, I made an account with roboflow, which offers image annotation services free for small projects. I only tried it a bit, but I can already tell it will be perfect for my purposes.
10/27/2023
Rubik's Cube Solution Generator
Yesterday, I finished annotating my images using Roboflow. I decided how I would keep track of the orientation of the cubes: each cube will have one of its colors be its identity; as the cube is moved around, we simply keep track of which face its identity is on at any given moment. To capture this orientation information along with the colors of the cubes themselves, I labeled each color like this CORNER_B_UP, EDGE_R_LEFT, CENTER_W_RIGHT. The directions up, left, and right simply indicate where the colors are present in the image - they don't necessarily refer to the left, right and up faces. Roboflow includes built-in model training with a finished dataset, so I gave that a try. On the first pass, my dataset achieved a mAP (Mean Average Precision) of around 15%, which is dreadfully low. On the second training, it achieved 25%. Though this figure is also highly imprecise, I was encouraged that my dataset could be improved through augmentation and preprocessing, two things to which Roboflow also provides easy access.
Roboflow provided a very nice workflow, and my previous problem, where I didn't have invididual labels but one large COCO JSON files, was solved. Each image now has a corresponding label file. Now I have a new problem: the SegmentationDataLoader from fastai requires labels that are masked images; Roboflow only provides labels in txt or json format. There are other ways for me to train a model, but I really want to use fastai since I'm trying to pursue the Practical Deep Learning for Coders course! I'm going to explore other image annotation options and see if any provide masking services. I'm still so new to image segmentation, so I probably also need to explore the topic as a whole more.
10/29/2023
Rubiks Cube Solution Generator
With more experimentation on Roboflow, I achieved a 75% mAP, a great boost to my confidence in this project! However, as I examined the results, I started to realize that my labeling system was not the one for the job; sure, the model could correctly identify a green sticker on a corner facing up, but which corner? Initially, I thought the instance segmentation would be performed in an order that I specified. However, the validation results were always presented based on confidence levels, so my labels could appear in any order! This would make the project completely fail at the purpose for which I was building it. Once again, I had to go through the painstaking process of relabeling everything. This time, I proceeding in a spiral pattern, labeling each color according to its location in the pattern, G_1, R_7, O\24. No matter what confidence levels are achieved, the labels themselves will tell me how the cubes are positioned.
As for the fastai problem mentioned in the previous entry, I decided to go another route for now; I'm using the ultralytics library. I'm completely new to this library and to the company that created it, Ultralytics, which is based out of Los Angeles, CA. I discovered it while using Roboflow. While viewing the list of export formats for my custom dataset, I noticed that there was a format entitled YOLOv8, which uses .txt files to store labels and a single YAML file to configure all the images and labels together. As stated previously, I quickly found that labels in the form of txt files would not work with fastai, which requires masked images for labels. On a whim, I did an internet search on "YOLOv8," and then I found the documentation on docs.ultralytics.com.
In my Colab Jupyter notebook, I imported the ultralytics library, downloaded the yolov8x-seg.pt, and I've been experimenting with the hyperparameters since. I wrote a simple Python script that reformats the YAML file in my dataset to work with the directories in Colab (I added the script to my dataset). I've mainly been trying out different numbers of epochs, trying up to 60. I got decent results! However, it's clear I need to add more images to the dataset to increase accuracy. I plan to add several images of solved Rubik's Cubes since I think that will accomplish my goals better. In other words, I can get every permutation of the colored squares with only 6 images.
10/31/2023
Rubiks Cube Solution Generator
Yesterday, I took 43 new images of my Rubik's Cube. It was in a solved state, which guarantees that each colored square will appear in each orientation multiple times. This should improve the accuracy of my dataset tremendously. Initially, I converted the images to PNG on my iPhone, but after I uploaded them to Google Drive and downloaded them to my laptop, I decided to make my life easier and convert them to jpegs. As PNG files, they took way too much time to upload, and I knew it would be a hassle to upload them to Roboflow. To convert them to jpegs, I used a LInux command line tool called ffmpeg, which takes a single file as input and convert it to whatever file format is specified. I needed to convert 43 images, so I wrote a simple bash script to convert them all with one command:
#!/bin/bash
counter=0
for filename in *;
do
ffmpeg -i $filename $counter.jpg
((counter++))
done
Then, I uploaded the images to Roboflow. Dreading the task of annotating all these new images by hand, I decided to take advantage of Roboflows label assist tool, which takes predictions from a previously trained model and uses them as a starting point for labeling. To do this, I needed a model trained on my already-annotated dataset. However, I had used up all my free credits for model training in Roboflows ecosystem, so I set about doing a custom training in Google Colab. I trained the model for 100 epochs, and I was very pleased with the result! The model now appears to be pretty accurate (though there's still room for improvement). Then, using Roboflows API, I uploaded the trained model to my dashboard; it was a fairly easy process. Now, I'm annotating the images and trying to get label assist to work. So far it hasn't worked as expected so I reached out to customer support and they are helping me figure out the problem.
11/1/2023
Rubiks Cube Solution Generator
Though I'm still improving my dataset by adding more images, I decided to upload the most recent trained model to huggingface.co. I did it for a few reasons. First, I'm following the philosophy of building out an application end-to-end as quickly as possible. That way I can see how the whole thing hangs together and I can optimize it more strategically. This is all in keeping with the Minimum Viable Product strategy. Second, having the Hugging Face Space will make testing much easier. Now I can capture images with my phone and run inference on them in a matter of seconds - no more converting the file, uploading it to Google Drive, downloading it, and then running inference on it. Last, it's been very useful to learn how to use Gradio more and how to prepare a Hugging Face Space.
11/2/2023
Rubiks Cube Solution Generator
I got my app running in a Hugging Face Space, but I encountered a significant problem that I wasn't able to resolve today. When I use the app on my phone and capture a video with the camera, the output image is rotated 90 degrees counter-clockwise. Right away I thought about what happened when I transferred my images from the iPhone to my laptop, which runs Ubuntu: they appeared in that same erroneous orientation, 90 degrees counter-clockwise. Using Image Viewer on my laptop, I corrected the orientation of each image before uploading them to my dataset project in Roboflow. I didn't think much more about it.
When running my app on my laptop, I encounter no problems (except for prediction results that needs improving), but when I run the app on my iPhone and the input image has anything other than a square aspect ratio, the output image comes out rotated. I consulted this fix, Fix Image Rotation on iOS, and borrowed some of the code to use in the inference() function in my gradio interface, but it didn't work as expected. However, it got me learning about EXIF (Exchangeable Image File Format) data. I learned that on iOS images taken in portrait mode are stored landscape with information added to the EXIF data that they need to be rotated to be properly displayed. This method of storing seems to "outsource" the cost of rotating the image to the image viewer whereas another form of storage might actually transpose all the pixel data to accurately represent the actual orientation of the image.
With this newfound information, I can posit that when I take a photo on my iPhone and run it through my app, the EXIF data is being stripped and the output image has nothing to specify how it should be displayed, so it displays in its actual form in memory. How can I intercept the image as it passes through my inference function and correct the EXIF data? This is what I was trying to do with my previous solution attempts. I'll keep trying!
11/5/2023
Rubiks Cube Solution Generator
I’ve been hard at work on this thing the past few days. I spent a lot of time getting to know Gradio and I’m excited by its possibilities. Eventually, I want to use the AnnotatedImage class for the output image. It would improve the look, make the output interactive, and make it much easier for the user to verify the results. I added a slider to allow users to control the models prediction confidence.
I also finished annotating the new images, all by hand since the label assist still refused to work, a bug that was acknowledged by a Roboflow team member. (I suppose I can’t really say by hand since Roboflow allows me to make use of Metas Segment Anything Model (SAM), which means I don’t have to draw polygons all day) Finishing this tedious task allowed me to train the model again, and it improved by almost 10% (at 84.2%)! I think I can do better, however.
Now, I’m experimenting with removing some of the Data Augmentations I applied in Roboflow. For instance, I have always applied a random -15 to 15 degrees rotation to the dataset, but I removed it on this latest training session (version 9). I suspect that it is a detriment to this models accuracy instead of a boon. Rotations might run the risk of making the model think its seeing a cube with a different color facing up.
As for the fiasco with the EXIF data, I decided to table that. When I’m testing in my Hugging Face Space, I simply always take landscape pictures. The portrait orientation doesn’t work at all.
11/6/2023
Rubiks Cube Solution Generator
A few updates:
- Removing the random -15 to 15 degrees data augmentation actually produced a model with a lower mAP.
- I tried training a model using no data augmentations and only one preprocessing step, Auto-Orient, and the model achieved a mAP of 89.2%, the highest yet, but the model was still, strangely outperformed by version 8, which has an mAP of 84.2% (version 8 has more variability in the dataset do to its preprocessing and augmentations, so even though it has a lower mAP, it is able to handle a wider range of input).
- After Roboflows label assist failed to function the first time, I corresponded with a representative and she explained that it might be failing because the model I used had augmentations and preprocessing applied. This time around, I trained a model (version 13) with the express purpose of getting the label assist to work: I applied no preprocessing or augmentations. It still failed!
- I took a look at Roboflows dataset health check feature, and I noticed that several of my classes were underrepresented in the dataset. I realized it's because several of my images contain unsolved Rubiks Cubes. As I've gotten a better grasp of the needs for the dataset, I've started using only images of solved cubes since it's much easier to keep track of the number of classes represented and it doesn't harm the accuracy of the model. I made the difficult decision to delete all the unsolved cube images, leaving only 59 images. Then, I tagged all the images with their configurations, e.g. ybo, rwb, bow, and I made a list of all 24 possible configurations to see which ones need more images. I found I need over 100 new images if I'm to bring all configurations up to the same level of representation as that of the most represented.
- Given the previous two points, it's clear I need a new labeling solution. I definitily need some from of auto-labeling - I'm not going to hand label over 100 new images! I'm currently exploring a platform called Neptune AI.
11/8/2023
fast.ai Lesson 3 & Rubiks Cube Solution Generator
Yesterday, I watched the third lesson of fast.ais Practical Deep Learning for Coders course. It centered on the how of deep learning, how neural nets works, matrix multiplication, gradient descent, and all that wizardry. Though I've understood it before, I found it difficult to grasp this time around - it could just be a different teaching style, or I'm a bit rusty. Either way, I'll have to revisit these topics to solidify them. In this lesson, Jeremy Howard made an intriguing point which I paraphrase here: "Try to train a model on the first day of your project. That way you can get a sense for how much work you have ahead. If you spend all your time building, cleaning, and labeling the dataset, you might end up doing unnecessary work."
I think I've done a tremendous amount of unnecessary work in this project! My first labeling concept proved to be a poor fit for my objective (account written here), so I pivoted to a new implementation, rearranging what I'd already done. I've proceeded in this manner pretty much the whole time. Yesterday when I performed the health check on my dataset, it was a wake up call, one I'd already received before but ignored. I think I wrote somewhere that with my system of labeling, _R_1, O_23, I'd only need six images total to cover every class equally. I don't think I really took this to heart when I thought it. Now, I've duplicated my project on Roboflow, and I deleted all the unsolved images. Moreover, I pared down the image collection to that of YOB, BYO, OBY, RGW, WGR, and RWG. By increasing the number of these images by equal amounts, I should never have any class underrepresented. Indeed, that is what happened. I have 18 images, increased to 44 images with data augmentation steps.
11/10/2023
Rubiks Cube Solution Generator
I've tried a lot of things since the last entry. I tried using the Tuner class from ultralytics to tune the models hyperparameters, and though I've figured out how it works, I'm still hazy on how to best use it in my project. I tried using an MLOPs tool, namely Neptune AI, which tracks the metadata of each model training session. In essence, it makes it easier to keep track of changes and tweaks made across each training session. I kept having problems getting Neptune to recognize my API_TOKEN, which I think was the result of a bug. I decided to remove Neptune for now. My latest dataset, v2ver5, consists of 30 training images and 6 validation images. It has no preprocessing or augmentation applied in Roboflow. The first training results were not impressive - something like mAP50 at 62% and mAP50-95 at 65%. I need to figure out how to apply augmentation with ultralytics. I probably also need to add more images to the dataset. Also, I want to experiment with passing specific arguments to the Trainer object, gaining more control over the hyperparameters.
11/14/2023
Rubiks Cube Solution Generator - UPDATE
A few days ago, I decided to subscribe to Paperspace Gradient, as Jeremy Howard suggested in Lesson 3. I migrated my Rubik's Cube project and set to work. Right away, I encountered numerous mind-numbing complications: Ultralytics model Trainer class could not find the train and valid folders no matter how many times I reconfigured the paths in the YAML file and the dataset folder hierarchy; then I found out that Ultralytics automatically prepends the dataset folder to the train and valid paths, so I changed that. Further similar complications arose and I slowly, tediously worked through them. To make things worse, Paperspace doesn't seem to respect changes I make to files even after I save them: I have to stop and restart the remote machine for the changes to take effect - perhaps there's a user error here. Ultimately, I found that the way I formatted the paths to directories in Google Colab is much more manual. In Paperspace, I was able to leave the data.yaml file completely alone, not calling my function specify_dataset_dir.py on it. Finally, I got the model to start training, but then I faced another roadblock. For some reason, the Trainer couldn't open the images and labels files even though it knew where they were. I'd had enough. I chalked it up to lack of experience. I figured I should leave this project alone, focus on the Practical Deep Learning for Coders course, and possibly return to my project when I have a better idea of how to structure my projects.
fast AI Practical Deep Learning for Coders
I'm working through Chapter 4 of the book associated with this course, Deep Learning for Coders with fastai and PyTorch. Here's my answers to the questionnaire this far:
-
How is a grayscale image represented on a computer? How about a color image?
Grayscale: a rank-2 tensor of pixels with each pixel represented by a single 8-bit unsigned integer types. Color: also a rank-2 tensor of pixels, yet where each pixel is represented by three 8-bit unsigned integers according to an RGB color space (perhaps a fourth uint8 for alpha). -
How are the files and folders in the MNIST_SAMPLE dataset structured? Why?
Images are organized into folders that are named after the label of those images. For example, the images that contain ‘3’ are organized into a folder named ‘3’. This is a convenient way to store the data since no extra files for labels are needed; the labels can simply be fetched with the from_folder_func() in fast AI. -
Explain how the "pixel similarity" approach to classifying digits works.
We get the average of the pixel values of all images of a certain label to create a generalized image that will function kind of like a mask. Then, we compare each pixel of some input image to the mask, getting the absolute value difference between them. We label the image according to whatever mask differs the least. -
What is a list comprehension? Create one now that selects odd numbers from a list and doubles them.
It is a concise way to generate a list that bypasses the for loop syntax. example = [num for num in num_list if num % 2 != 0] -
What is a "rank-3 tensor"?
It is a tensor that has three dimensions. -
What is the difference between tensor rank and shape? How do you get the rank from the shape?
Rank is a tensors number of dimensions while shape is the length of each dimension. You can get the rank from the shape viarank = len(tensor.shape). -
What are RMSE and L1 norm?
They are both loss functions designed to calculate the difference between two tensors. RMSE stands for Root Mean Squared Error and L1 Norm is the mean absolute difference. Because it squares the difference, RMSE is severe with big mistakes and lenient with small ones. L1 Norm is linear in its calculation. -
How can you apply a calculation on thousands of numbers at once, many thousands of times faster than a Python loop?
By running the calculations in parallel on a GPU, which, unlike a CPU, can haves thousands of cores. -
Create a 3×3 tensor or array containing the numbers from 1 to 9. Double it. Select the bottom-right four numbers.
data = [[1,2,3],[4,5,6],[7,8,9]] tns = torch.tensor(data) print(tns) tns *= 2 print(tns) selection = tns[1:3,1:3] print(selection)
11/16/2023
fastai Practical Deep Learning for Coders - Chapter 4
- What is broadcasting?
_Broadcasting is one of the most important features of PyTorch to understand. When a program is set to perform arithmetic on two tensors of different ranks, PyTorch will autmatically increase the rank of the smaller-rank tensor to match that of the larger. This is known as broadcasting. When PyTorch does this, it doesn't actually change the smaller-rank tensor in memory; instead, it simply performs the calculation for each layer in the additional dimension of the higher-ranking tensor. - Are metrics generally calculated using the training set, or the validation set? Why?
Metrics are calculated using the validation set. This is to avoid a problem known as overfitting, where the models weights are too closely coupled with the training set images, preventing the model from generalizing well to any images outside the training set. By calculating the loss on the validation set, which is not used in the training epochs, we avoid this problem.
11/19/2023
fastai Practical Deep Learning for Coders - Chapter 4 Questionnaire
- What is SGD?
Stochastic Gradient Descent is a means to automate the learning process. After calculating the loss, the difference between the predicted and actual value for an input, SGD is used to automatically reduce it: it gets the gradient, which is the derivative of the loss function at the value of the weight to be reduced (or increased). SGD is what allows deep learning models to be practical - without it, the practitioner would have to adjust weights manually, and as the complexity of the model increases, this becomes an impossible task in any reasonable amount of time. - What are the seven steps in SGD for machine learning?
- Initialize the weights to random values.
- Run the images through, using the weights to predict the correct value.
- Calculate the loss (difference of predictions and targets).
- Calculate the gradient for each weight.
- Step the weight toward the desired value, reducing it by the gradient times the learning rate.
- Repeat 1 through 5.
- Finish when a specified number of epochs is reached or the model is good enough.
- How do we initialize the weights in a model?
We initialize them with random values. We could initialize them with values that reflect preliminary trends in the data, but it turns out that random values works just as well. - What is "loss"?
Loss is the difference between the predicted value of a piece of data and the actual value. It’s main purpose is to be machine-readable, to be a reliable output on which to base Stochastic Gradient Descent. - Why can't we always use a high learning rate?
With a high learning rate, there is a risk that updating the weights will result in an overcorrection, which at best causes the model to take extra steps to reduce the loss and at worst causes the models adjustments to diverge, moving away from the minimal value. - What is a "gradient"?
A gradient is the derivative of a function at a particular value. This is how PyTorch handles derivation: instead of returning another function, it merely calculates and returns the derivative for an individual input to the function. - Do you need to know how to calculate gradients yourself?
Not to operate a deep learning model since PyTorch calculates the gradients for us. However, it’s useful to know how to calculate them ourselves for the purpose of understanding deep learning better.
AlphaGo - The Movie
I finally got around to watching this award-winning documentary. It covered the two matches in which AlphaGo defeated two seasoned Go players, Fan Hui and Lee Sodol, the latter of which was the world champion. Fan Hui lost all five games and Lee Sodol lost four out of five, having one history-making victory (one of Sodol's moves was declared a "divine move," move 78, the move that is said to have won him the game). Both players had complicated experiences; their emotions ranged from awe to dismay, and both of them underwent minor identity crises as their Go-playing prowess was displaced by AlphaGo. Lee Sodol actually retired from professional play shortly thereafter! There was one point that really stuck out to me: someone said that AlphaGo is going to change how Go is played for generations to come. AlphaGo kept employing strategies that no human has hitherto considered, and its revolutionary moves are bound to enter into the canon of Go strategy. This is an interesting angle on AI: what new ways of thinking will humanity uncover with the aid of AI? We have at least one example with AlphaGo. It's plain that AI will change the efficiency with which we perform important tasks, but this documentary got me thinking about how it will fundamentally change human thinking, reasoning, and behavior - perhaps philosophy.
11/21/2023
fastai Practical Deep Learning for Coders - Chapter 4
- Why does SGD use mini-batches?
This question has sent me on a tortuous path, desperately trying to understand the difference between batch, mini-batch and stochastic gradient descent; what a loss function (research which led me to cost functions, which are apparently different) does to calculate gradients; and how backpropagation works. Ugh. I feel like I'm just spinning my wheels! I'm gaining understanding, but then some new piece of information completely upsets what I thought I understood. It isn't coming together yet.
Mini-batches are used as a middle road, a balance between evaluating the entire training data at once and evaluating a single item at a time. The former takes an immense amount of compute and provides more stable gradients while the latter takes much less compute but provides more unstable gradients (in minimizing the loss, it does succeed to some extent, but the local minima are always danced around). Mini-batches allow SGD to gain some of the advantages of evaluating a full-batch while avoiding the costly compute as the single item evaluation does.
11/22/2023
fastai Practical Deep Learning for Coders - Chapter 4
- Why can't we use accuracy as a loss function?
Accuracy is not responsive enough. If we adjust gradients based off it, we are likely to see very little change since accuracy will only change when false positives turn into true positives, an event that will not occur frequently. We need a loss function that is much more responsive, yielding a value that is more sensitive to adjustments to the weights. - Draw the sigmoid function. What is special about its shape?
The sigmoid function is confined to the range of [0,1] in which the largest rate of change is in the middle where the slope of the function is steeper. As the x-value shifts left, the rate of change in slope gradually decreases, approaching 0 ever more slowly. The same is true of the x-value shifting right and approaching 1. - What is the difference between a loss function and a metric?
A loss function is meant to aid the neural network in the automated learning process while a metric is meant to be interpreted by a human, who can then make decisions, such as whether to alter any hyperparameters. - What is the function to calculate new weights using a learning rate?
_w -= gradient(w) * lr, where the learning rate (lr) is usually set to some small value like 0.001 so that the network doesn't take too big of steps in minimizing the loss. - What does the DataLoader class do?
The DataLoader class can organize our dataset into mini-batches, and further, it can shuffle them for each epoch. By varying which data items go into which mini-batch for each epoch, we can help our model better generalize, which is what we want!
11/26/2023
fastai Practical Deep Learning for Coders - Chapter 4 Questionnaire
- Pseudocode
- Initialize weights to random values.
- Run images through the network.
- Calculate the loss.
- Calculate the gradients.
- Step the weight vector by subtracting the gradient vector times the learning rate.
- Create a function that, if passed two arguments [1,2,3,4] and 'abcd', returns [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')]. What is special about that output data structure?
def func(arr1, arr2):
return list(zip(arr1, arr2))
The data structure created is the format of a dataset. which we will pass into our model for training.
27. What does view do in PyTorch?
The view method in PyTorch changes the shape of a tensor while preserving the data. Here's some example code:
import torch
# Initialize a rank-2 tensor with shape 2x2 (two rows, two columns).
ex1 = torch.randn(2, 2)
# shape is an alias for size in PyTorch
print(ex1.shape) # Prints `torch.Size([2, 2])`
print(ex1) # Prints `tensor([[-0.9847, -2.5266], [-0.2092, -0.8132]])`
# Change shape of rank-2 tensor to 4x1 (four rows, 1 column).
ex1 = ex1.view(4, 1)
print(ex1.shape) # Prints `torch.Size([4, 1])`
print(ex1) # Prints `tensor([[-0.9847], [-2.5266], [-0.2092], [-0.8132]])`
- What are the "bias" parameters in a neural network? Why do we need them?
The bias parameters are the intercept portion of a linear functiony = wx + b. If we receive an input pixel of value zero, then the product ofwxwill be zero. This is a problem since there's nothing we can do with a zero value. We need thebiasto ensure that there is some non-zero value to work with.
11/27/2023
fastai Practical Deep Learning for Coders - Chapter 4 Questionnaire
- What does the @ operator do in Python?
The @ operator performs matrix multiplication on the operands. - What does the backward method do?
Backward refers to backpropagation. It is the method that calculates the gradients for our weights. - Why do we have to zero the gradients?
When we run the backward method, PyTorch will simply add the gradient values to whatever value is already present, and we want that value to be zero since we want to calculate the gradients for each batch individually; we don't want the accumulation of the gradients over the whole training period (the model would never actually learn this way). - What information do we have to pass to Learner?
We have to pass the dataset, which we created by zipping the image tensor together with the label tensor into a list of tuples, the architecture, our optimization function of choice (Stochastic Gradient Descent), our loss function of choice, and what metric we want to use. - Show Python or pseudocode for the basic steps of a training loop.
for x,y in dl:
pred = model(x)
loss = loss_func(pred, y)
loss.backward()
parameters -= parameters.grad * lr
- What is "ReLU"? Draw a plot of it for values from -2 to +2.
_ReLU stands for Rectified Linear Unit. It is an activation function that ensures the activations are all zero or positive. Here is the graph: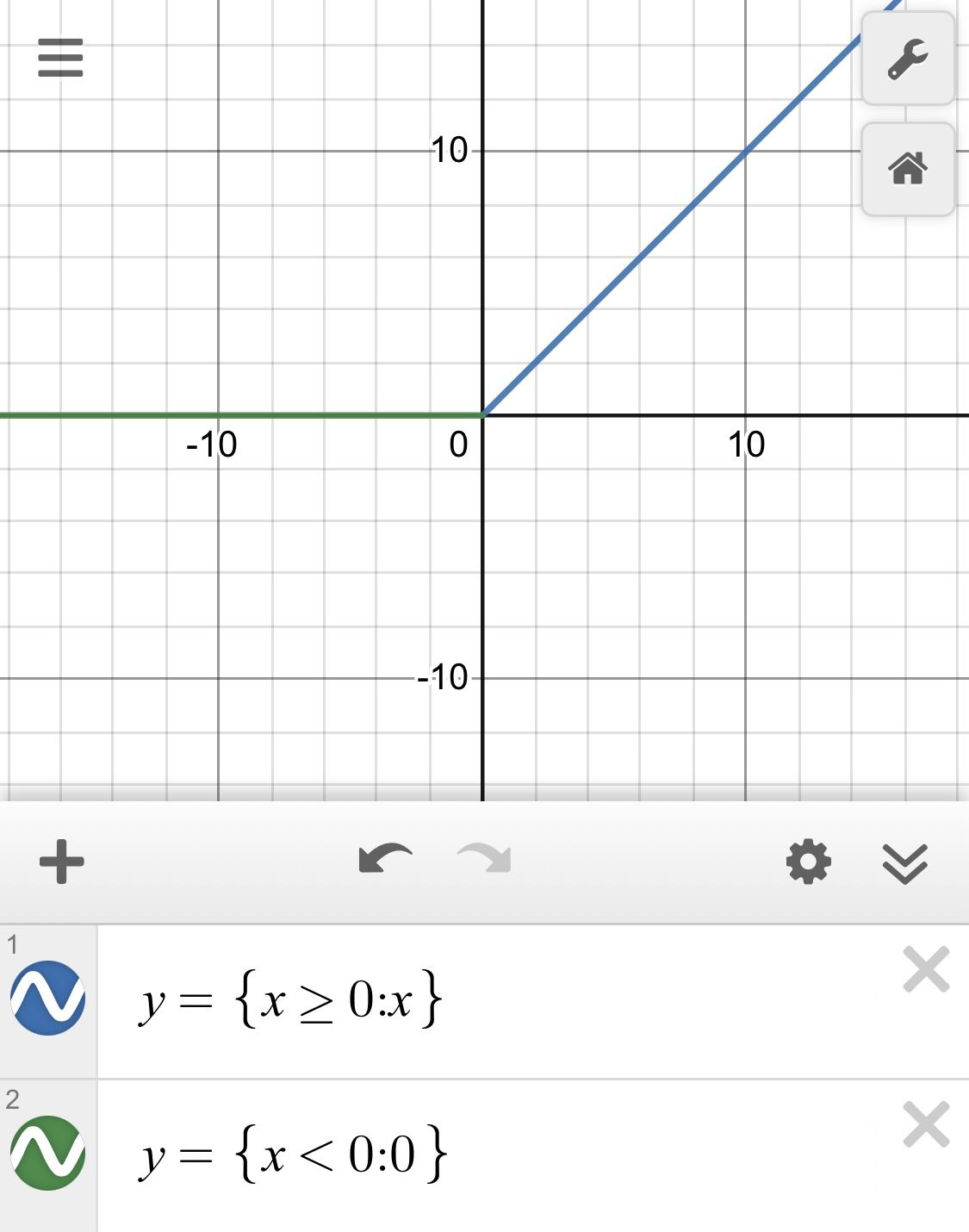
- What is an "activation function"?
An activation function is a function that for each neuron in a layer takes the value (the activation) calculated from the dot product of the input vector and the neurons parameter vector and squeezes it into a smaller range, often in the ranges of [0,1] and [-1,1]. Given that these functions "upset" the linearity of the dot product calculate between inputs and parameters, a layer of activation functions is referred to as a nonlinearity. - What's the difference between F.relu and nn.ReLU?
F.relu is an implementation of ReLU that stands on its own so to speak.nn.ReLUis the same thing implemented as a module. We are required to use it when specifying an activation function inside ann.Sequentialobject instantiation. - The universal approximation theorem shows that any function can be approximated as closely as needed using just one nonlinearity. So why do we normally use more?
While a single nonlinearity is enough, using more than one can enhance the models performance. By using more nonlinearities (and by extension more layers), we can have fewer parameters connecting each layer and achieve better performance! In other words, more layers with fewer parameters connecting them is better for performance than fewer layers with more parameters connecting them.

{kind=link}
12/5/2023
fastai and MNIST
I had to take a break. I think started to burn myself out with how much time I spent on answering the final question of fastai chapter 4 questionnaire:
Complete all the steps in this chapter using the full MNIST datasets (that is, for all digits, not just 3s and 7s). This is a significant project and will take you quite a bit of time to complete! You'll need to do some of your own research to figure out how to overcome some obstacles you'll meet on the way.
I didn't solve the problem on my own. While I appreciate fastai tremendously, something about the layout of chapter 4 made it difficult to parse out which code snippets I actually needed. I had a general idea of what needed to be done, but there were several details I just couldn't surmount. I decided to consult a tutorial. I found this excellent video Building a Neural Network FROM SCRATCH (no Tensorflow/PyTorch, just numpy & math), which helped me understand how everything worked tremendously! I replicated the example code in Paperspace, and once again I encountered some bugs. I combed through my code, compared it to the code from the video multiple times, made several changes, but I couldn't figure out what was keeping the model from improving during training. It simply remained around 10% throughout the epochs. Fed up, I copy-pasted the code from the kaggle notebook (made available in the videos description) and ran it. Of course, it worked.
I'm trying to be as honest as possible here. I learned a lot from the video, and conceptually almost everything makes sense, but from an execution standpoint, I'm still getting lost and frustrated with the details, e.g. transpose this matrix but not that one, how to use NumPy (I'm still fairly new to its vectorization and parallel computing capacities), how to slice arrays using more concise yet complex syntax. Here's my notes to the video: Neural Network from Scratch Notes.
Landing a Job in Tech - North Seattle Tech Talks MeetUp
Yesterday, I attended a MeetUp about landing a job in technology. I was already familiar with much of the content, but it was still helpful to attend, even if only for the exercise of putting myself out there and attending live events. Next time, I'll be better about contributing to the chat and getting my name out there. Here were a few significant takeaways:
- Try working for a nonprofit; they may be less competititve.
- Sometimes the market is unfriendly - educate yourself while things are bad and be ready for when they're good.
- Practice answers to behavioral questions. interviewprepnow.com
- Google lets you study their interview packet for up to 6 months before an interview. Amazon does something similar. Ask your potential employer for prep material.
12/7/2023
Algorithms for Searching, Sorting, and Indexing
I think I've decided to pursue CU Boulders MS-CS degree program. To gain admission to the program, one has to complete a pathway. In other words, one has to prove one can pass a given course, and I've chosen the Algorithms pathway. To prepare for this, I'm taking the two courses leading up to the Pathway, of which Algorithms for Searching, Sorting, and Indexing is the first. This course is accompanied by the Introduction to Algorithms 3rd Edition textbook. Each module will have an assigned reading. In the first assigned reading, Chapter 1, there are several exercises questions to help benchmark the readers comprehension. I'll answer those questions here:
1.1-1 Give a real-world example that requires sorting or a real world example that requires computing a convex hull.
- Sorting example: web-scraping images of dogs and sorting them alphabetically according to breed.
- Convex hull example: when defining a district in a city, deciding which buildings on the perimeter to include and exclude and how to draw the line accordingly.
1.1-2 Other than speed, what other measures of efficiency might one use in a real-world setting?
One might need to consider how much space is used, especially if space is limited. Energy is another consideration; an algorithm might be fast, but it is still useless if running it proves too high a load on the energy reserves.
1.1-3 Select a data structure that you have seen previously, and discuss its strengths and limitations.
Hash tables: strengths include O(1) insertion time and lookup time (excepting situations where collisions have been resolved with linear probing). Weaknesses include clustering, when data starts to cluster together in the table, it will only increase the likelihood of clustering with additional insertions; hash tables are static in size and this can be a problem if the amount of input data needs to increase dramatically - we have to resize the table and rehash everything, a potentially expensive operation.
1.1-4 How are the shortest-path and traveling-salesman problems given above similar? How are they different?
The traveling-salesman problem could be construed as a problem in which we need to find several shortest paths concurrently. In other words, the traveling-salesman problem could be viewed as multiple shortest-path problems. However, this comparison only extends so far since each shortest path in the traveling salesman problem is actually a loop, which may in fact need to overlap itself.
1.1-5 Come up with a real-world problem in which only the best solution will do. Then come up with one in which a solution that is "approximately" the best is good enough.
I think of the Therac-25, a computer-controlled radiation therapy machine that operated in the 1980s. This machine had a fatal bug in its software, resulting in the deaths of several patients, who were blasted with radiations levels in some cases 10 times that of the expected number of rads. With a radiation therapy machine, it is ESSENTIAL that the absolute best solution be implemented. (Not sure if this answers the question accurately, but I can’t think of anything else at the moment.
12/10/2023
CU Boulder Algorithms Course 1 Week 1
Exercises from the course textbook, Introduction to Algorithms.
1.2-1 Give an example of an application that requires algorithmic content at the application level, and discuss the function of the algorithms involved.
My unfinished application is an example: it takes in the state of an unsolved Rubik’s Cube and generates a list of moves needed to solve it. It does this by simulating the moves in a data structure that I designed. Moreover, to manipulate this data structure, I had to specify algorithms that would define what a single turn means; then, I took this base algorithm, multiplied it and combined it, and made algorithms that actually resemble the algorithms that a person learns when solving a Rubik’s Cube.
1.2-2 For inputs of size n, insertion sort runs in 8n^2 steps, while merge sort runs in 64nlgn steps. For which values of n does insertion sort beat merge sort?
I made an equation, 8n^2 < 64nlgn, simplified it, and then plugged in test values until I arrived at the rough answer of n < 44.
1.2-3 What is the smallest value of n such that an algorithm whose running time is 100n^2 runs faster than an algorithm whose running time is 2^n.
n~=14
12/13/2023
CU Boulder Algorithms Module 1
Exercises from the course textbook, Introduction to Algorithms, Foundations Section 2.
2.1-3 Write pseudocode for linear search, which scans through the sequence, looking for v. Using a loop invariant, prove that your algorithm is correct. Make sure that your loop invariant fulfills the three necessary properties.
LINEAR-SEARCH(A, v)
for i = 1 to A.length
if v == A[i]
return i
i = i + 1
return NIL
LOOP INVARIANT: at the start of each iteration, v is not in the subarray A[1, i - 1]. Initialization: our first set, A[1, 0] is effectively an empty set, so it is trivially true that v is not in A[1, 0]. Maintenance: at the start of the i-th iteration, we have already examined the element at every previous index i. Termination: we will have v or NIL.
2.1-4 Consider the problem of adding two n-bit integers, stored in two n-element arrays A and B. The sum of the two integers should be stored in binary form in an (n + 1)-element array C. State the problem formally and write pseudocode for adding the two integers.
ADD-BINARY(A, B)
C = array(A.length + 1)
for i = A.length down to 1
carry = A[i] && B[i]
C[i + 1] = (A[i] + B[i]) % 2
C[0] = carry
return C
12/14/2023
CU Boulder Algorithms Module 1
2.2-1 Express the function $n^3/1000 - 100n^2 - 100n + 3$ in terms of $\Theta$-notation.
$\Theta(n^3)$
2.2-2 Consider sorting $n$ numbers stored in array $A$ by first finding the smallest element of A and exchanging it with the element in $A[1]$. Then find the second smallest element of $A$, and exchange it with $A[2]$. Continue in this manner for the first $n-1$ elements of $A$. Write pseudocode for this algorithm, which is known as selection sort. What loop invariant does this algorithm maintain? Why does it need to run for only the first $n-1$ elements, rather than for all $n$ elements? Give the best-case and worst-case running times of selection sort in $\Theta$-notation.
SELECTION-SORT(A)
for i = 1 to A.length - 1 // line 1
smallest = i // line 2
for j = i + 1 to A.length // line 3
if A[j] < A[smallest] // line 4
smallest = j
j = j + 1 // line 6
swap(a[i], a[smallest]) // line 7
i = i + 1 // line 8
LOOP INVARIANT: Initialization: at the start of each iteration, the array is divided into a left and right subarray, with the left subarray elements always being smaller than the right subarray elements (trivially true at the beginning since the left subarray is of size 0). Maintenance: each time the smallest number from the right subarray is added to the left subarray, each element in the left subarray remains smaller than each element in the right subarray. Termination: the right subarray contains one element and it is the largest element in the full array.
The loop only needs to run for the first $n - 1$ elements since we don't need the final element to swap with itself.
$c_1(n - 1) + c_2(n - 1) + \displaystyle\sum_{k=1}^{n-1} c_3k(n - 1) + \displaystyle\sum_{k=1}^{n-1} c_4k(n - 1) + \displaystyle\sum_{k=1}^{n-1} c_6k(n - 1) + c_7(n - 1) + c_8(n - 1)$
Best Case: $\Theta(n^2)$
Worst Case: $\Theta(n^2)$
2.2-3 Consider linear search again. How many elements of the input sequence need to be checked on the average, assuming that the element being searched for is equally likely to be any element in the array? How about in the worst case? What are the average-case and worst-case running times of linear search in $\Theta$-notation? Justify your answers.
On average, $\frac{(n + 1)}{2}$ elements must be checked, which we calculate with $\frac{1}{n}\displaystyle\sum_{k=1}^{n}n$. For the worst case, we must check all the elements, so $n$ elements. These figures expressed in $\theta-notation$ are $\theta(n)$ for the average case and $\theta(n)$ for the worst case.
2.2-4 How can we modify almost any algorithm to have a good best-case running time?
We include an initial conditional statement that checks to see if the input data is already equal to the output data the algorithm would have yielded. For example, in Selection Sort, we could include an initial branch that checks to see if the array is already sorted; such a procedure would run in $\Theta(n)$ time and therefore bypass the standard $\theta(n^2)$ time.
12/15/2023
CU Boulder Algorithms Module 1
2.3-3 Use mathematical induction to show that when $n$ is an exact power of 2, the solution of the recurrence $\newline T(n) = \begin{cases} 2 & \text{if } n = 2 \newline 2T(n/2) + n & \text{if } n = 2^k, \text{ for } k > 1 \end{cases}\newline$ is $T(n) = nlgn$.
Merge Sort continually divides the array in half until it reaches a level where all subarrays are of size 1. Even though we are repeatedly modifying the original array, each level still has $n$ elements, where n is the size of the original array. The recurrence equation captures this aspect with the $n$ addend in the recursive case, adding in the cost of combining the subarrays of a given array. The other term of the recursive case, $2T(n/2)$, is the recursive element, getting the running times for “conquering” the two subarrays of a given array, a calculation with must be performed all the way to the base case. $lgn$ tells us how many times 2 divides into $n$, which tells us how many levels will be in our recursion tree. For each level, there are $n$ combinations to be made, so $T(n) = \Theta(nlgn)$.
12/18/2023
CU Boulder Algorithms Module 1
2.3-4 We can express insertion sort as a recursive procedure as folows. In order to sort $A[1 ..n]$, we recursively sort $A[1..n-1]$ and then insert $A[n]$ into the sorted array $A[1..n-1]$. Write a recurence for the running time of this recursive version of insertion sort.
To help understand the problem, I first wrote pseudocode:
INSERTION-SORT(A, n)
if n > 2
INSERTION-SORT(A, n - 1)
for i = n down to 1
if A[i + 1] < A[i]
SWAP(A[i + 1], A[1])
In the worst case, the for loop will execute a number of times equal to the value of n at a given level of recursion. In other words, we can expect the for loop to run $n + (n - 1) + (n - 2) + ... + 2$ times, which can be expressed with the following recurrent equation:
$$ T(n) = \begin{cases} 1 & \text{if } n = 2 \newline T(n - 1) + n & \text{if } n > 2 \end{cases} $$
2.3-5 Referring back to the searching problem (ex. 2.1-3), observe that if the sequence $A$ is sorted, we can check the midpoint of the sequence against $v$ and eliminate half of the sequence from further consideration. The binary search algorithm repeats this procedure, halving the size of the remaining portion of the sequence each time. Write pseudocode, either iterative or recursive, for binary search. Argue that the worst-case running time of binary search is $\Theta(lg,n)$.
BINARY-SEARCH(A, bgn, end, v)
if bgn <= end
mid = (bgn + end) / 2
if v == A[mid]
return mid
if v > A[mid]
result = BINARY-SEARCH(A, mid + 1, end, v)
return BINARY-SEARCH(A, bgn, mid - 1, v)
return -1
After the initial function call, every time BINARY-SEARCH is called, the search space is halved. Our algorithm will only have to consider one of the halves at each recursive level (whereas in Merge Sort both halves must be operated on). Moreover, at each recursive level, the algorithm only examines one element, checking whether our key is greater than, less than, or equal (in which case our work is done). Therefore, the question must be answered: for an array of size $n$, how many times can it be divided in half before a subarray of size 1 is reached. Mathematically, we can show how many times a number can be divided by 2 before reaching 1 with $log_2$. Reaching a subarray of size 1 is the worst case, so worst-case running time is $\Theta(lg,n)$.
Recurrence Equation:
$T(n) = \begin{cases} \Theta(1) & \text{if }n = 1 \ \Theta(n / 2) + \Theta(1) & \text{if }n > 1 \end{cases}$
2.3-6 Observe that the while loop of lines 5-7 of the INSERTION-SORT procedure in Section 2.1 uses a linear search to scan backward through the sorted subarray $A[1..j-1]$. Can we use a binary search instead to improve the overall worst-case running time of insertion sort to $\Theta(n,lg,n)$?
Using binary search instead of linear search does optimize the insertion sort algorithm by reducing the number of comparisons required for any given subarray to $lg,n$. This tempts one to think that we can achieve $O(n,lg,n)$ by multiplying the number of comparisons, $lg,n$ by the number of subarrays the algorithm will generate with insertion sort, which is $n$. However, this does not consider the fact that we still must peform a number of swaps equal to the length of the subarray for every subarray to move all elements into the correct positions. Therefore, it is not possible to optimize insertion sort to $O(n,lg,n)$ with this method.
12/19/2023
CU Boulder Algorithms Module 1
2.3-7 Describe a $\Theta(n,lg,n)$-time algorithm that, given a set $S$ of $n$ integers and another integer $x$, determines whether or not there exist two elements in $S$ whose sum is exactly $x$.
For this problem, I not only wrote pseudocode:
FIND-SUM(S, n, x)
for i = 1 to S.length
diff = x - S[i]
result = BINARY-SEARCH(S, i + 1, n, diff)
if result != -1
return (i, result)
return (-1, -1) // No terms added to the sum.
I also wrote a small program in C++:
#include <iostream>
int binarySearch(int A[], int bgn, int end, int key) {
if (bgn < end) {
int mid = int((bgn + end) / 2);
if (key == A[mid]) {
return mid;
}
if (key < A[mid]) {
return binarySearch(A, bgn, mid, key);
}
return binarySearch(A, mid + 1, end, key);
}
return -1;
}
std::pair<int, int> findSum(int S[], int n, int x) {
for (int i = 0; i < n; i++) {
int diff = x - S[i];
int result = binarySearch(S, i + 1, n, diff);
if (result != -1) {
return {i, result};
}
}
return {-1,-1};
}
void printArray(int A[], int n) {
for (int i = 0; i < n; i++) {
std::cout << A[i] << ' ';
}
std::cout << std::endl;
}
int main(int argc, char** argv) {
int key = std::stoi(argv[1]);
int S[] = {1,2,3,4,5,6,7,8,9,10};
printArray(S, 10);
std::pair<int, int> p = findSum(S, 10, key);
std::cout << p.first << ' ' << p.second << std::endl;
return 0;
}
This algorithm, FIND-SUM(S, n, x), indeed runs in $\Theta(n,lg,n)$ time. FIND-SUM() iterates across all elements in the array exactly once $\Theta(n)$. For each for loop iteration, we run BINARY-SEARCH on all elements to the right of the current element in question, an operation that takes:
$\Theta(lg,(n - i)), \text{ where }i\text{ is the }ith\text{ iteration of the for loop.}$
Therefore, the following accounts for the binary search that is performed $n$ times, for each iteration of the for loop:
$\displaystyle\sum_{i=1}^{n}lg(,n - i)$
which (supposing $n=10$) expands to
$$ lg(1) + lg(2) + lg(3) + lg(4) + lg(5) + lg(6) + lg(7) + lg(8) + lg(9) \newline lg(1 \cdot 2 \cdot 3 \cdot 4 \cdot 5 \cdot 6 \cdot 7 \cdot 8 \cdot 9) \newline lg(9!) \approx 18 $$
This is a slight optimization over plain $\Theta(n,lg,n)$, which yields $10 \cdot lg(10) \approx 33$ steps. As n increases, this advantage dwindles, trending toward a $1:1$ ratio. Therefore, we may simply write the running time as $\Theta(n,lg,n)$.
12/20/2023
CU Boulder Algorithms Module 1
Problem 2-1 Insertion sort on small arrays in merge sort: Although merge sort runs in $\Theta(n,lg,n)$ worst-case time and insertion sort runs in $\Theta(n^2)$ worst-case time, the constant factors in insertion sort can make it faster in practice for small problem sizes on many machines. Thus, it makes sense to coarsen the leaves of the recursion by using insertion sort within merge sort when subproblems becomes sufficiently small. Consider a modification to merge sort in which $n/k$ sublists of length $k$ are sorted using insertion sort and then merged using the standard merging mechanism, where $k$ is a value to be determined.
I had to get some help for these problems!
a. Show that insertion sort can sort the $n/k$ sublists, each of length $k$, in $\Theta(nk)$ worst-case time.
Each subarray will take $\Theta(k^2)$ worst-case time to sort with insertion sort. We have $n/k$ number of subarrays, so the total time to sort is $n/k \cdot k^2$ or $\Theta(nk)$.
b. Show how to merge the sublists in $\Theta(n,lg(n/k))$ worst-case time.
The merge procedure will take $\Theta(n)$ no matter what since at every level of the recursion there are still $n$ elements, albeit divided up into subarrays, but every level will have $2^L$ subarrays of $\frac{n}{2^L}$ elements, where the layer in question is $L$ layers below the base layer. Therefore, the number of elements per layer is
$$ 2^L \cdot \frac{n}{2^L} = n $$
Ordinarily, we would run the merge procedure on $lg,n$ recursion levels, hence the usual $\Theta(n,lg,n)$. But with our insertion sort optimization, the merge routine is not called $lg,n$ times since we stop dividing before reaching subarrays of size 1. Suppose $n=8$ and $k=4$: we already know that our original array generates $lg,n$ recursive levels; it follows that our array of size $k$ will generate $lg,k$ recursive levels. We want the difference of $n$ recursive levels and $k$ recursive levels, so
$$ lg(n) - lg(k) = lg(n/k) $$
Finally, we get
$$ \Theta(n,lg(n/k)) $$
c. Given that the modified algorithm runs in $\Theta(nk + n,lg(n/k))$ worst-case time, what is the largest value of $k$ as a function of $n$ for which the modified algorithm has the same running time as standard merge sort, in terms of $\Theta$-notation?
$k$ only needs to be bounded by $\Theta(lg,n)$, or $k(n) \in \Theta(lg,n)$. $k$ can be any constant within that constraint.
d. How should we choose $k$ in practice?
$k$ should be as large as possible while still producing a running time less than that of ordinary merge sort.
Meeting with Steve and Wes
I had a meeting with a potential employer today! The opportunity is for part time work as a Python developer. It's project-based, which means my employment would cease upon completion of the project, or perhaps an opportunity to expand to full-time would be offered. I'm not sure. Either way, I'm excited just to have this opportunity in front of me. If I take it (and I plan to), it would be another great addition to my resume as well as a means to start making an impression among people in the industry - Steve no doubt has a myriad of connections. Anyway, I'm excited by this development, which was brought about by Wes, who heard of this opportunity and thought of me. I have to send Steve an email soon to confirm I'm on board, if they'll have me!
12/22/2023
CU Boulder Algorithms Module 1
Problem 2-2 Correctness of Bubblesort
BUBBLESORT(A) for i = 1 to A.length - 1 for j = A.length down to i + 1 if A[j] < A[j - 1] exchange A[j] with A[j - 1]
a. Let $A'$ denote the output of BUBBLESORT(A). To Prove that BUBBLESORT is correct, we need to prove that it terminates and that
$A'[1] \leq A'[2] \leq ... \leq A'[n],$
where $n=A.length$. In order to show that BUBBLESORT actually sorts, what else do we need to prove?
We need to show that there is a Loop Invariant that sorts a subproblem, which grows until it is the size of the original problem.
b. State precisely a loop invariant for the for loop in lines 2-4, and prove that this loop invariant holds. Your proof should use the structure of the loop invariant proof presented in this chapter.
Loop invariant: for every iteration of the inner loop, $A[j] \leq A[j...A.length]$. This is trivially true when $j = A.length$.
Initialization: when $j = A.length$, $A[j] \leq A[j...A.length]$ is trivially true since $A[j]$ is equal to itself.
Maintenance: when $A[j] < A[j - 1]$, the elements will be swapped. When $A[j] \geq A[j - 1]$, the elements will not be swapped. Therefore, when the loop index $j$ decrements, $A[j] \leq A[j...A.length]$.
Termination: when $j = i + 1$, $A[j] \leq A[j...A.length]$ and $A[1...j]$ will be in sorted order.
c. Using the termination condition of the loop invariant proved in part (b), state a loop invariant for the for loop in lines 1-4 that will allow you to prove inequality (2.3). Your proof should use the structure of the loop invariant proof presented in this chapter.
Loop Invariant: for every iteration of the inner loop $j$, $A[j] \leq A[j...A.length]$. This means that for every value of $i$, $i - 1$ will always be an element smaller than all elements in $A[i...A.length]$.
Initialization: $A[i - 1] \leq A[i...A.length]$ is trivially true since $A[i - 1]$ is meaningless at the start of the sorting operation.
Maintenance: Whenever the outer loop completes an iteration, inner loop $j$ has guaranteed that the smallest element in $A[i...A.length]$ is at $A[i]$ (proven by the Loop Invariant described above).
Termination: When the outer loop completes its final iteration, having, for every value of $i$, always placed the smallest element in $A[i...A.length]$ at $A[i], the array will be entirely sorted.
d. What is the worst case running time of bubblesort? How does it compare to the running time of insertion sort?
In the worst case (an array in descending order that we want in ascending order), Bubble Sort begins by making the largest number of swaps first and from there the number decreases by 1 for each iteration of the outer for loop. The total number of swaps is $\frac{n(n-1)}{2}$.
Conversely, in the worst case, Insertion Sort begins by making a single swap and the number of swaps increases by 1 for each iteration of the for loop (up to $n-1$ swaps). Therefore, we get the same running time as Bubble Sort --> $\frac{n(n-1)}{2}$.
12/28/2023
Inventory Manager
Yesterday, I started putting the finishing touches on this web app, e.g. configuring an app password to connect it to Gmail, resolving GitHub’s dependabot alerts. However, I discovered a bug: I noticed that the order previews in the finalize template were not displaying all the items in the order. Initially, I thought the session was the problem, that the data stored in the session was being dropped. Then I noticed that some information was getting through, but still not all, so I realized it couldn’t be the session. Next, I thought it could be related to the dependabot updates I approved, but some quick tests proved otherwise. Finally, I found the problem, and it was very simple: I was not indexing into the list of tuples correctly in the finalize template. I must have made a change in the code a while ago that changed the format of this list of tuples, and somehow I was unaware that it would affect the order preview in the finalize template.
CU Boulder Algorithms Module 1
Correctness of Horner's Rule
$P(x) = \displaystyle\sum_{k=0}^{n} a_kx^k = a_0 + x(a_1 + x(a_2 + ... + x(a_{n-1} + xa_n)...)),$
given the coefficients $a_0, a_1, ..., a_n$ and a value for $x$:
y=0
for i = n downto 0
y=a_i + x * y
a. In terms of $\Theta$-notation, what is the running time of this code fragment for Horner's Rule?
The running time is $\Theta(n)$, where $n$ is the degree of the polynomial. For every $ith$ operation in of the for loop, there are $c$ operations to carry out: 1 addition and 1 multiplication. If we're splitting hairs, the running time is therefore $\Theta(2n)$, but we drop the constant since it has next to no impact on the running time.
b. Write pseudocode to implement the naive polynomial-evaluation algorithm that computes each term of the polynomial from scratch.
// let "A" be an array of coefficients from
// lowest to highest degree for our polynomial.
for i = n down to 0
for j = i - 2 down to 0
x_raised = x_raised * x
y = y + A[i] * x_raised
This code snippet calculates the powers for every term, i.e. for a $nth$-degree polynomial, we have $n + 1$ operations, the first of which performs $n - 1$ multiplications, and each subsequent operation performs 1 fewer. So there are
$\frac{n(n-1)}{2}$ operations, which is a running time of $\Theta(n^2)$.
c. Consider the following loop invariant:
At the start of each iteration of the for loop of lines 2-3,
$y = \displaystyle\sum_{k=0}^{n-(i+1)} a_{k+i+1} x^k$.
Interpret a summation with no terms as equaling 0. Following the structure of the loop invariant proof presented in this chapter, use this loop invariant to show that, at termination, $y=\displaystyle\sum_{k=0}^{n} a_kx^k$.